import numpy as np
import ceviche_challenges
from ceviche_challenges import units as u
import ceviche
from inverse_design.brushes import notched_square_brush, circular_brush
from inverse_design.conditional_generator import (
new_latent_design, transform
)
from tqdm.notebook import trange
import autograd
import autograd.numpy as npaCeviche Challenges
Integration with ceviche challenges to test the optimization
import jax
import jax.numpy as jnp
from javiche import jaxit
import matplotlib.pylab as plt
import numpy as np
from inverse_design.local_generator import generate_feasible_design_mask
from jax.example_libraries.optimizers import adamspec = ceviche_challenges.waveguide_bend.prefabs.waveguide_bend_2umx2um_spec(
wg_width=400*u.nm, variable_region_size=(1600*u.nm, 1600*u.nm), cladding_permittivity=2.25
)
params = ceviche_challenges.waveguide_bend.prefabs.waveguide_bend_sim_params(resolution = 25 * u.nm)
model = ceviche_challenges.waveguide_bend.model.WaveguideBendModel(params, spec)def forward(latent_weights, brush):
latent_t = transform(latent_weights, brush) #.reshape((Nx, Ny))
design_mask = generate_feasible_design_mask(latent_t,
brush, verbose=False)
design = (design_mask+1.0)/2.0
return designbrush = circular_brush(5)
latent = new_latent_design(model.design_variable_shape, bias=0.1, r=1, r_scale=1e-3)No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)@jaxit()
def inner_loss_fn(design):
s_params, fields = model.simulate(design)
s11 = npa.abs(s_params[:, 0, 0])
s21 = npa.abs(s_params[:, 0, 1])
global debug_fields
debug_fields = fields
global debug_design
debug_design = design
return npa.mean(s11) - npa.mean(s21)
def loss_fn(latent):
design = forward(latent, brush)
return inner_loss_fn(design)# Number of epochs in the optimization
Nsteps = 150
# Step size for the Adam optimizer
def step_size(idx):
"""reducing the stepsize linearly for Nsteps (stabilize afterwards just in case)"""
start = 0.1
stop = 5e-3
return start*(stop/start)**(idx/Nsteps)
step_size = 0.01def visualize_latent(latent):
global debug_design, debug_fields
design = forward(latent, brush)
s_params, fields = model.simulate(design)
debug_design = design
debug_fields = fields
visualize_debug()
def visualize_debug():
global debug_design, debug_fields
if not isinstance(debug_fields, np.ndarray):
debug_fields = debug_fields._value
debug_design = debug_design._value
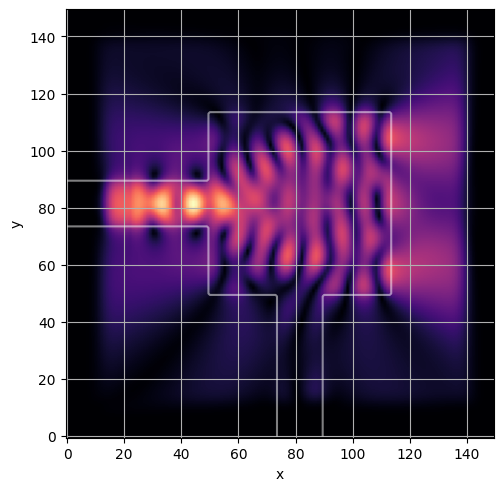
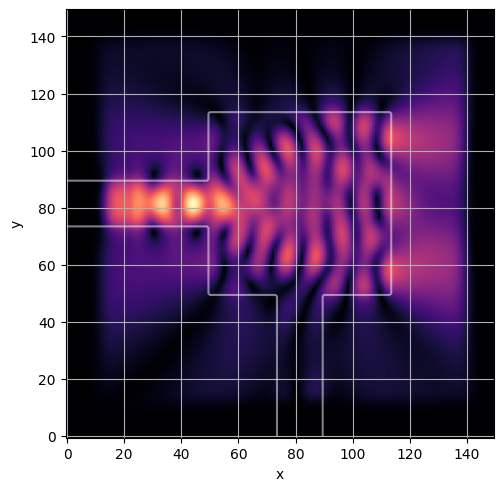
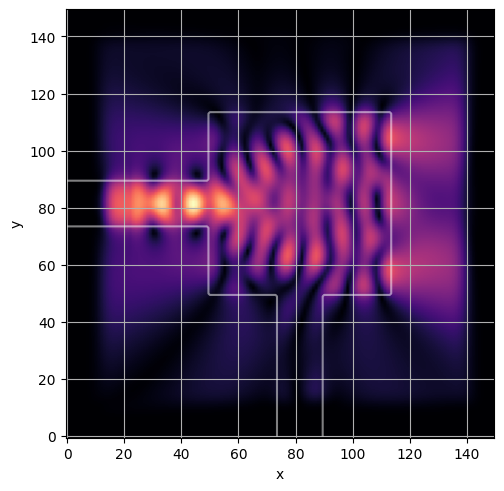
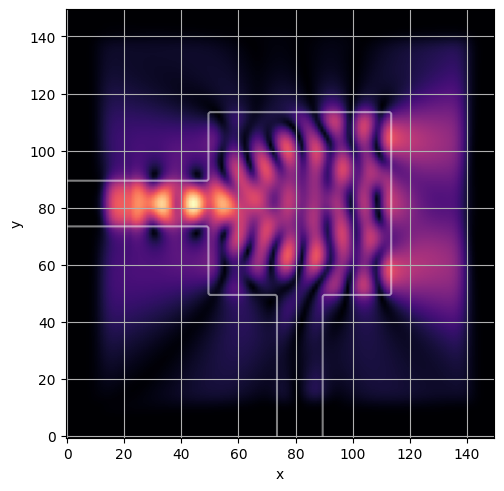
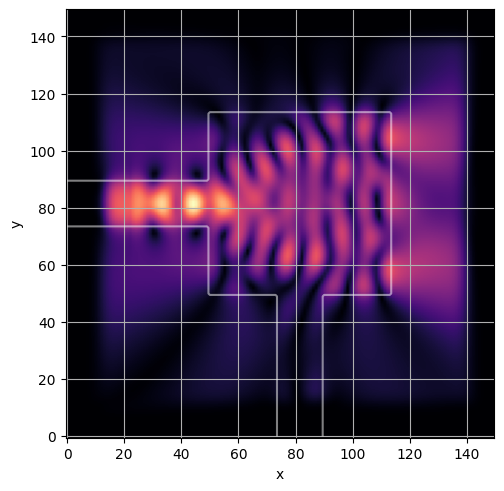
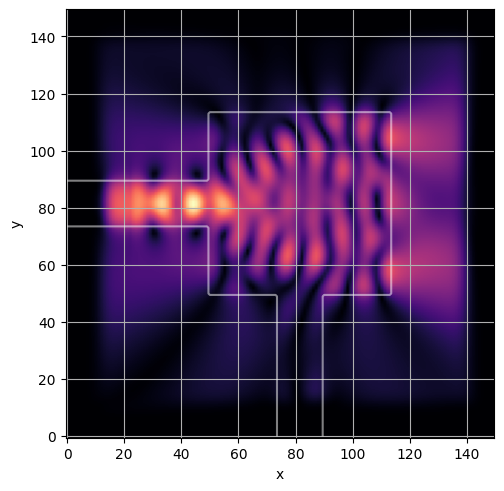
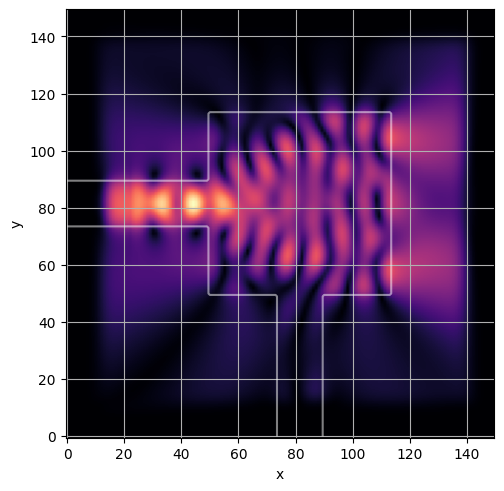
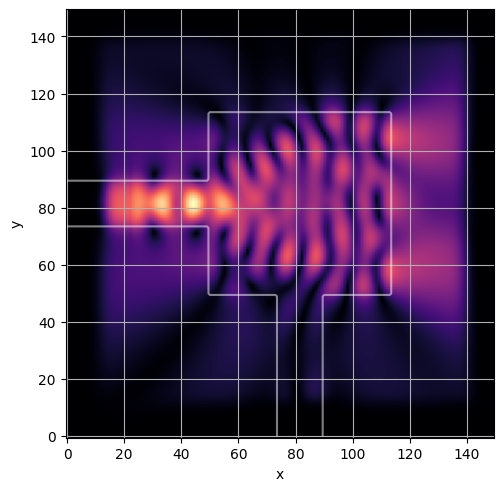
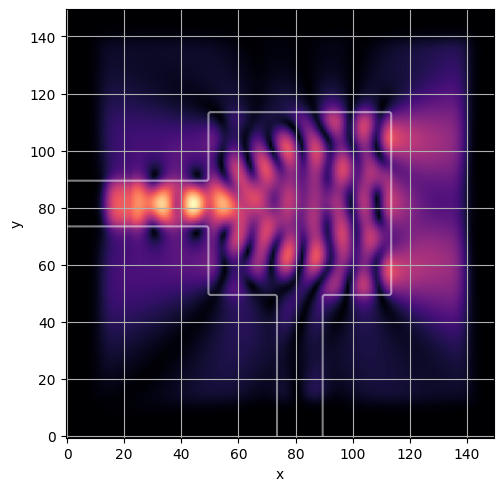
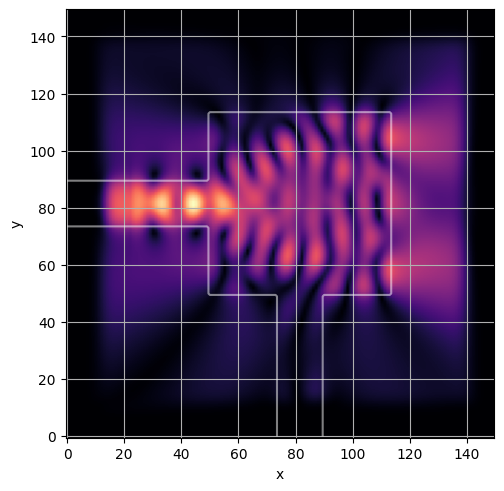
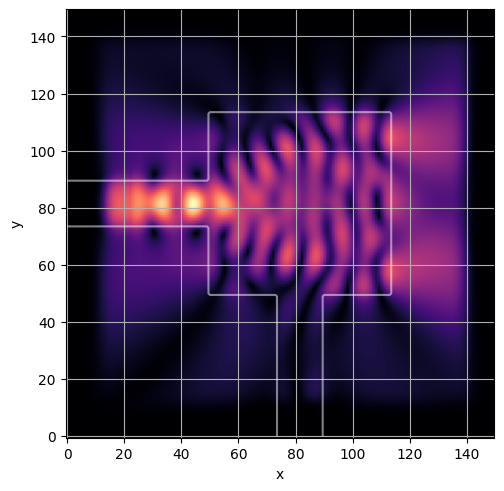
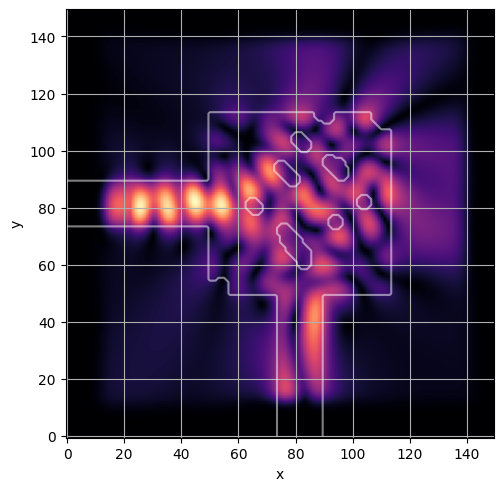
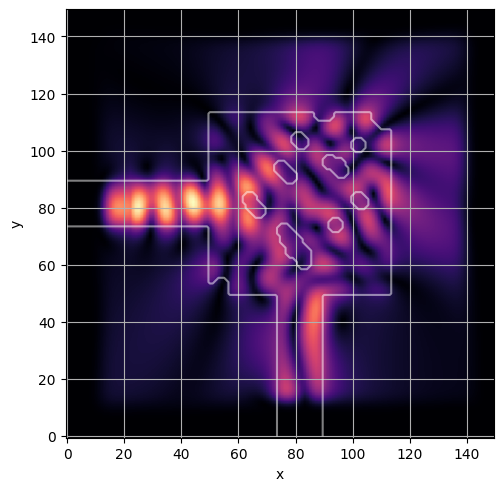
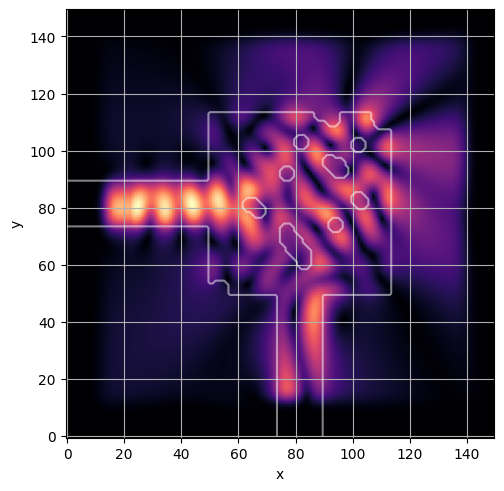
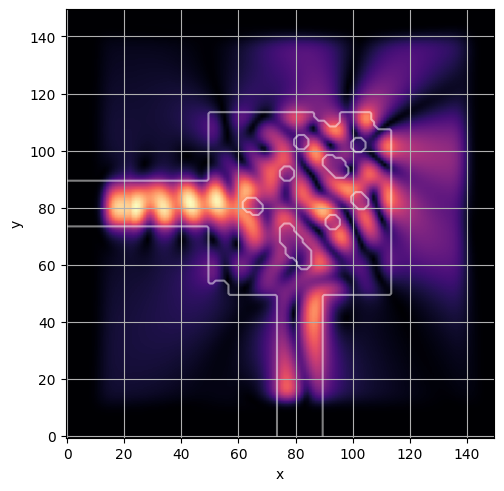
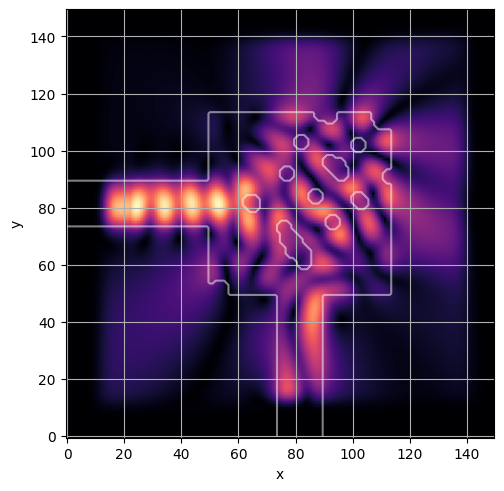
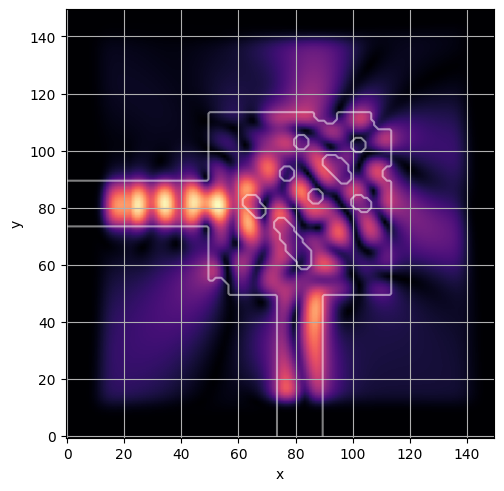
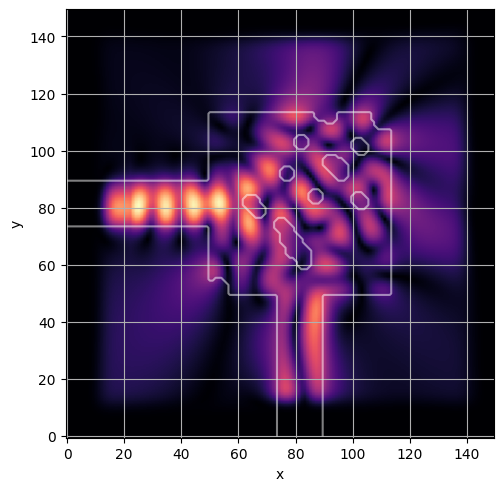
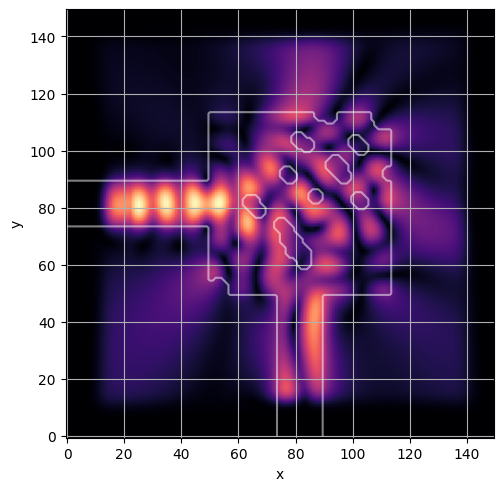
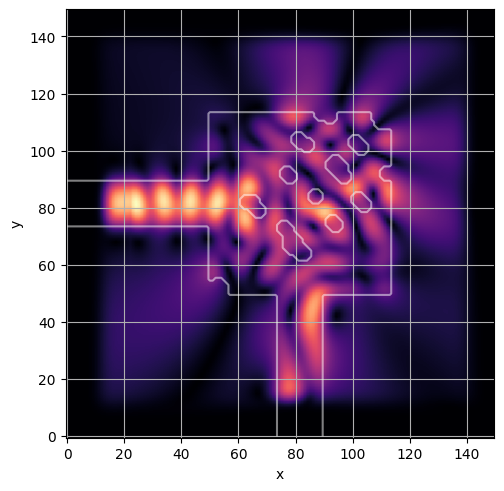
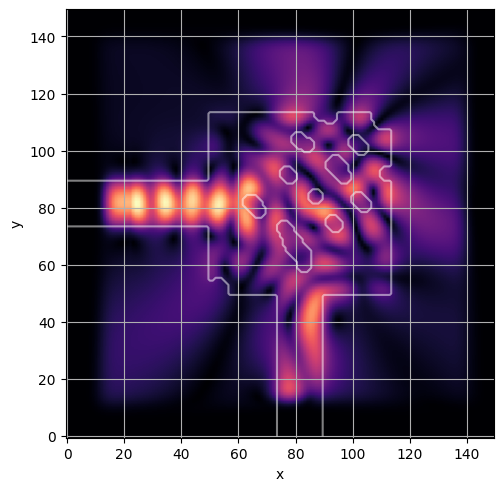
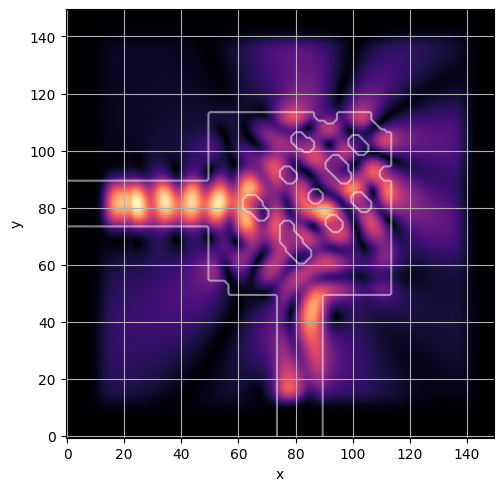
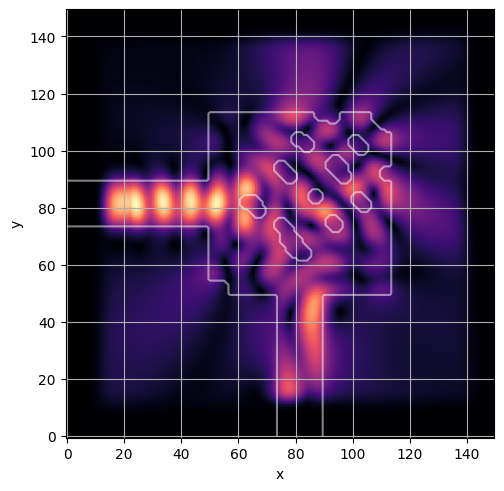
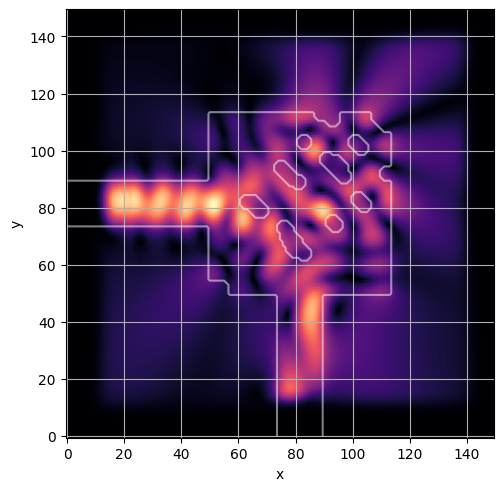
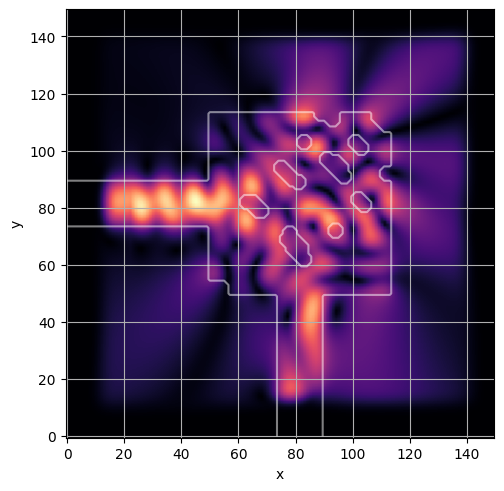
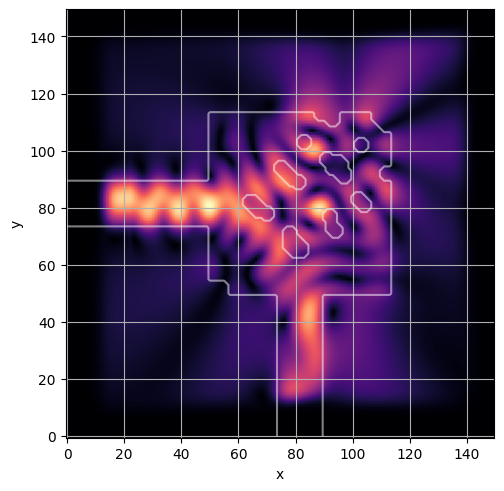
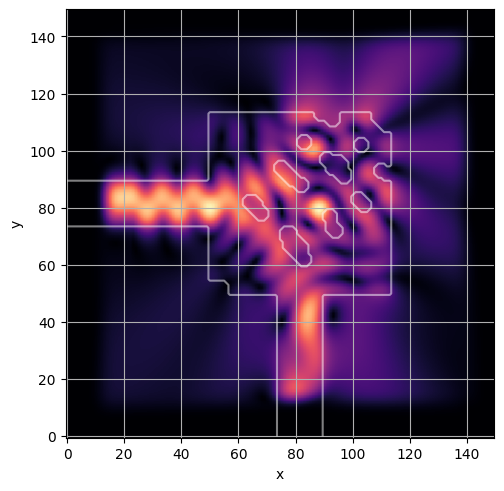
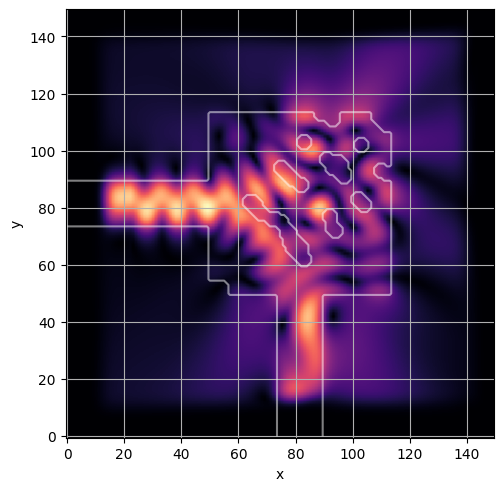
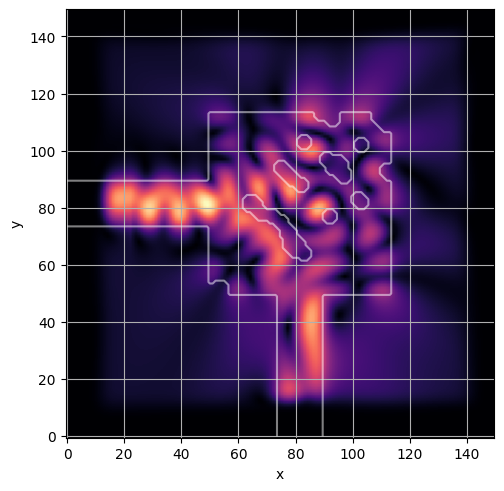
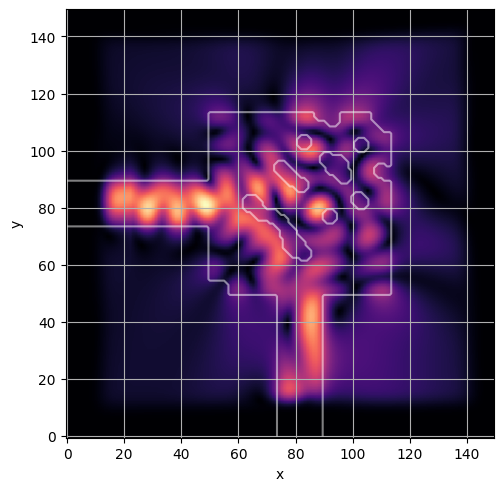
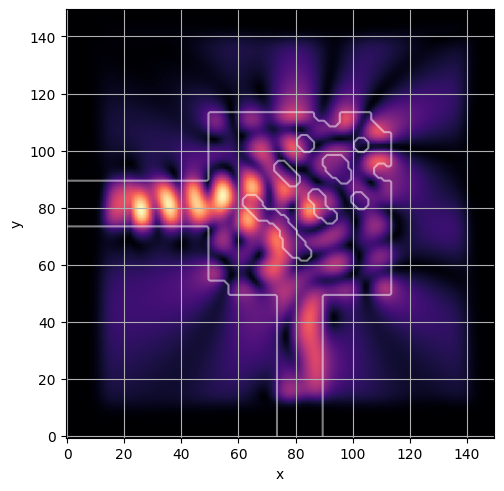
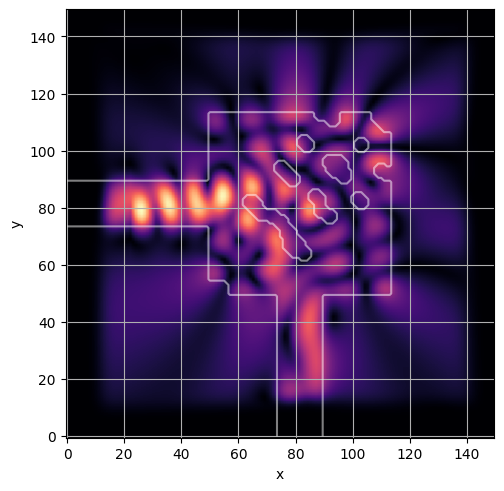
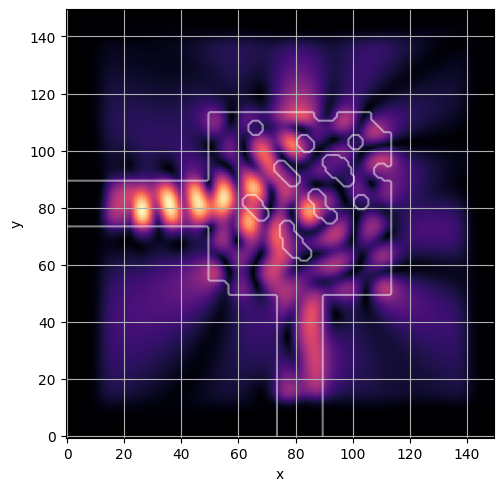
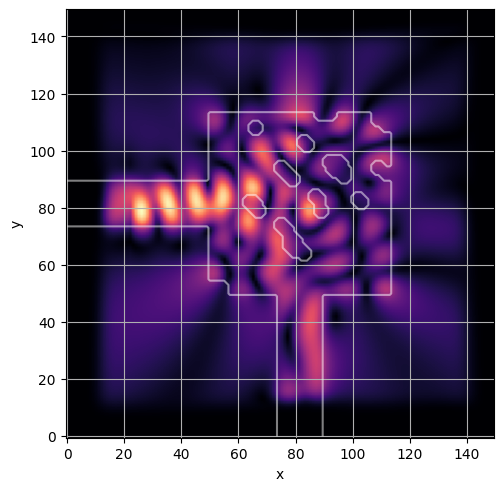
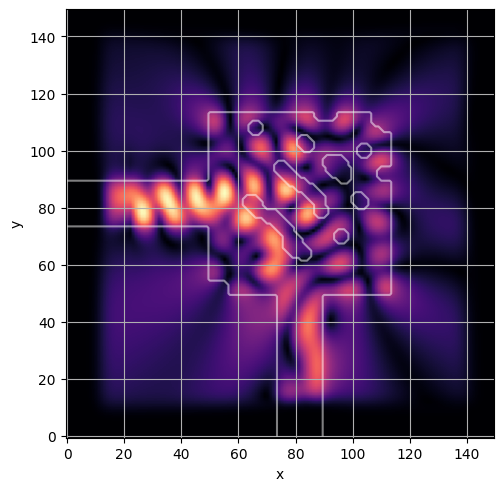
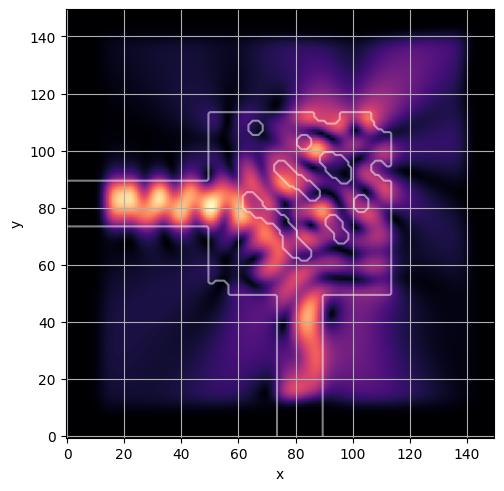
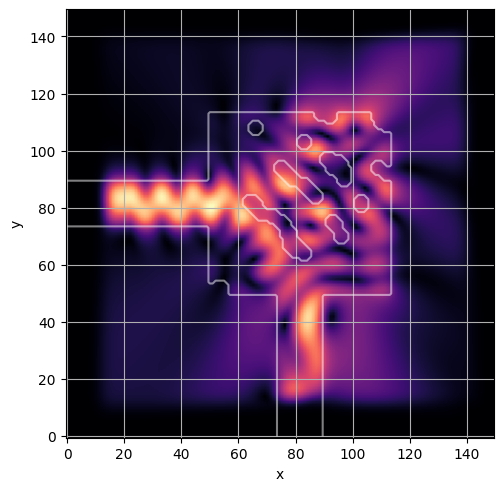
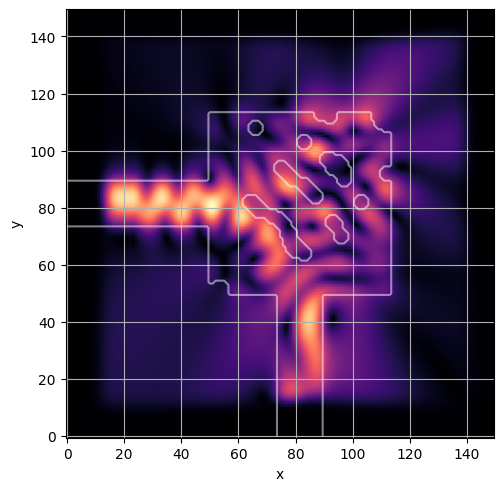
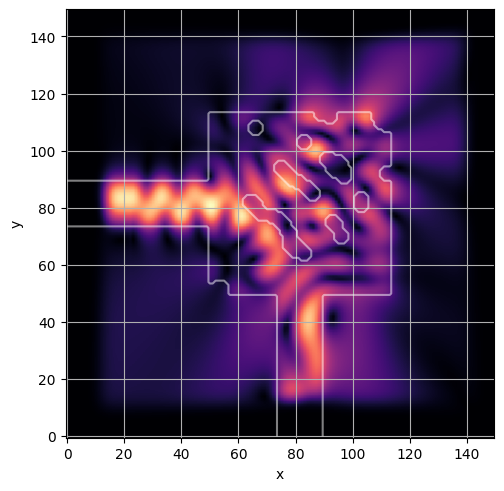
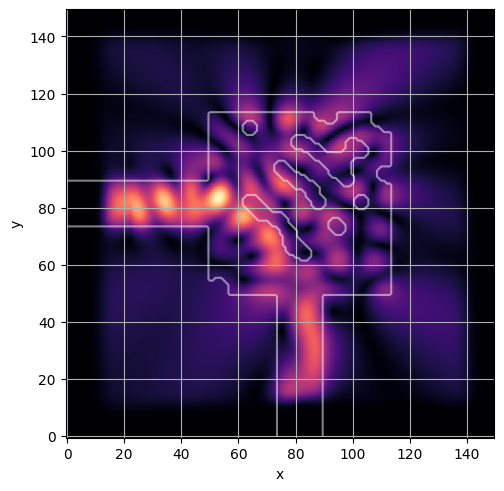
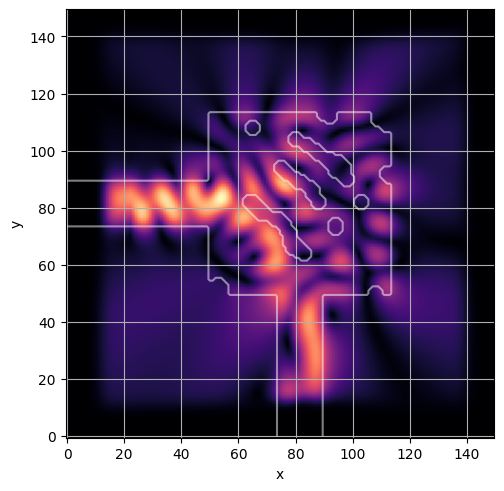
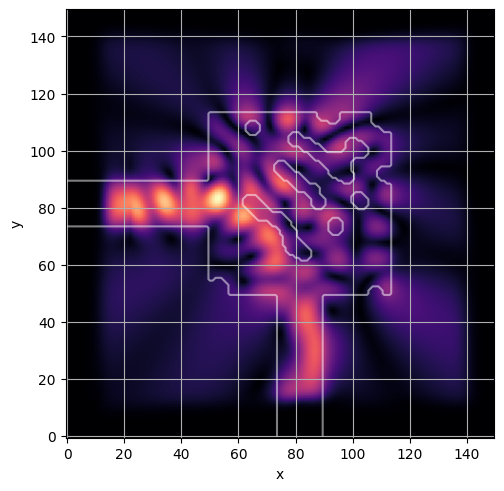
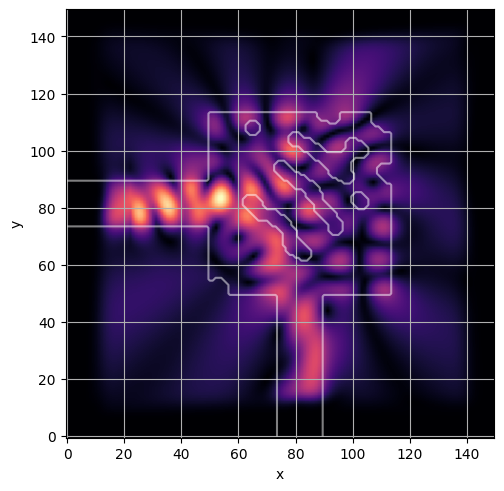
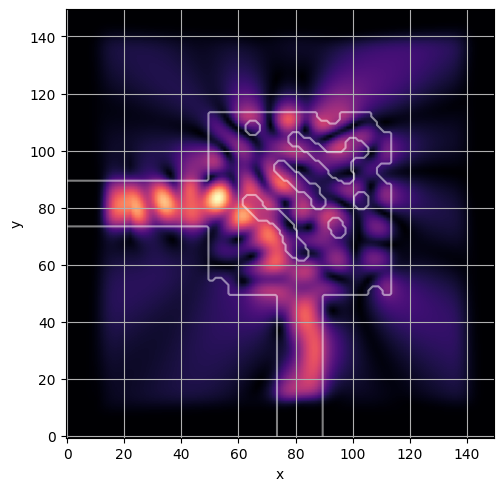
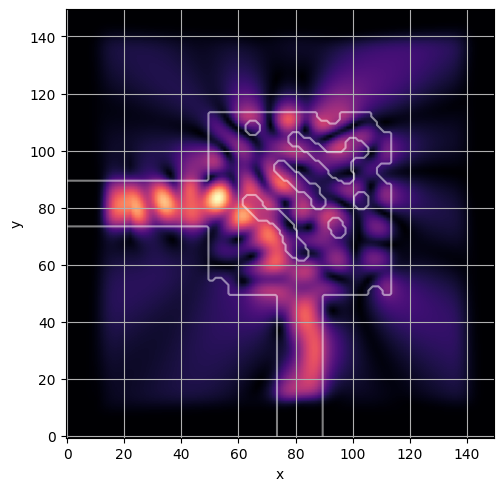
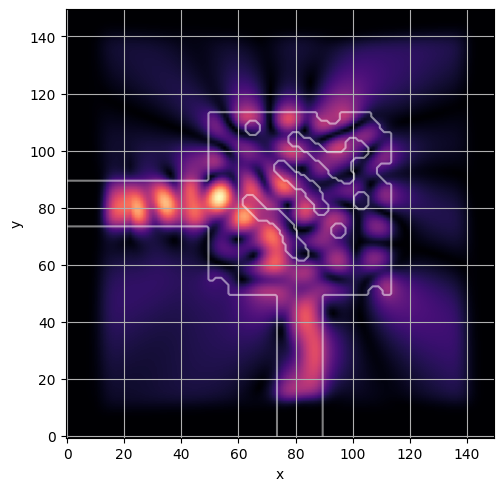
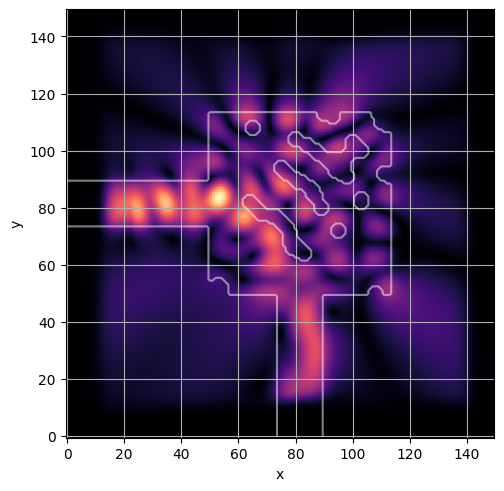
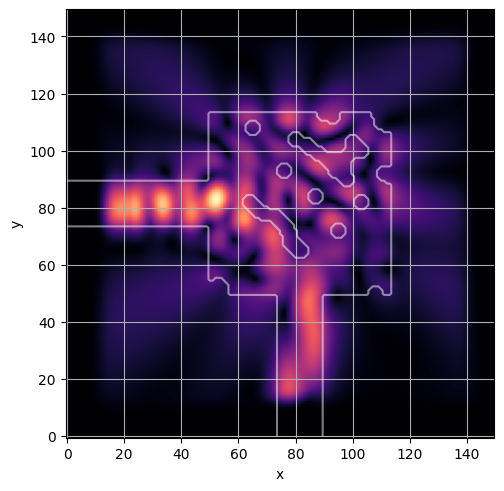
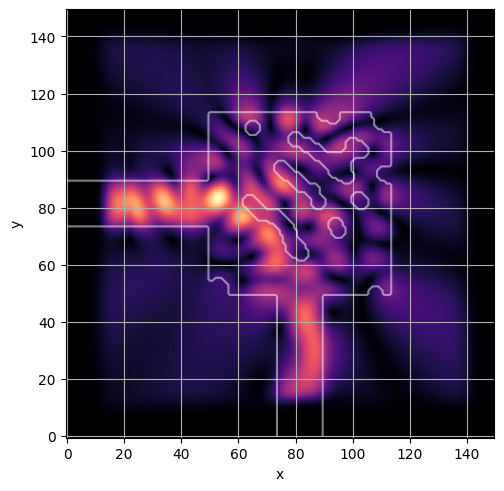
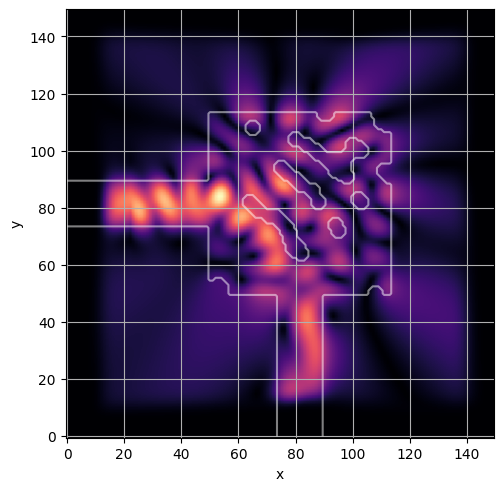
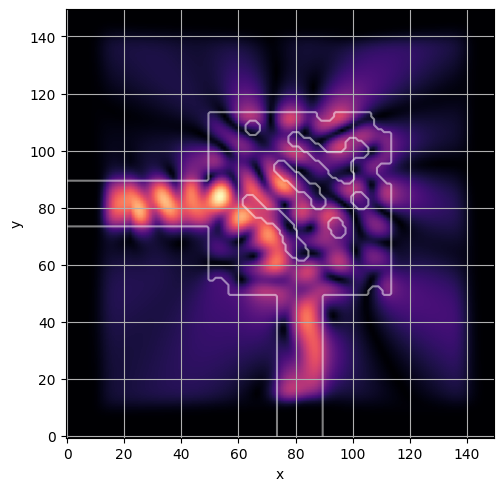
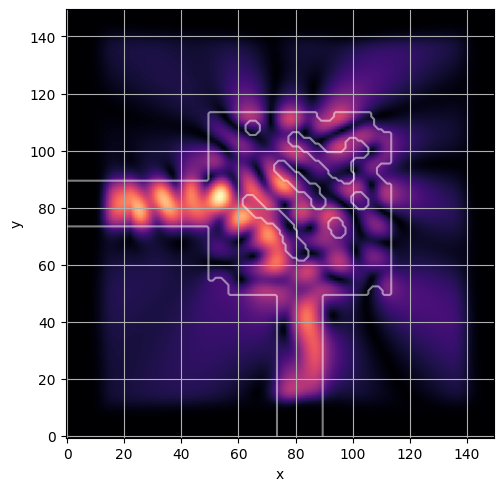
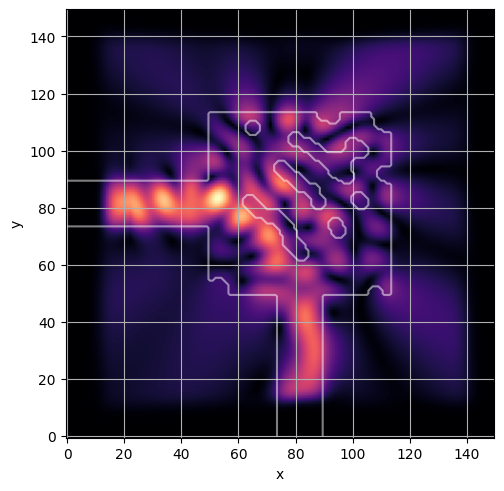
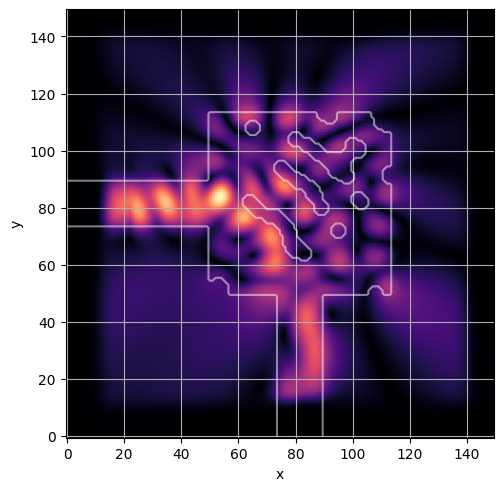
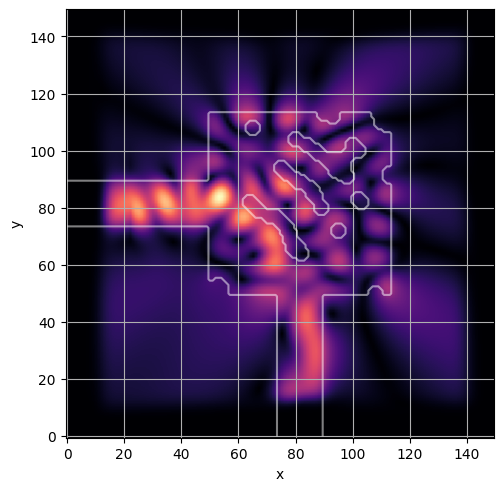
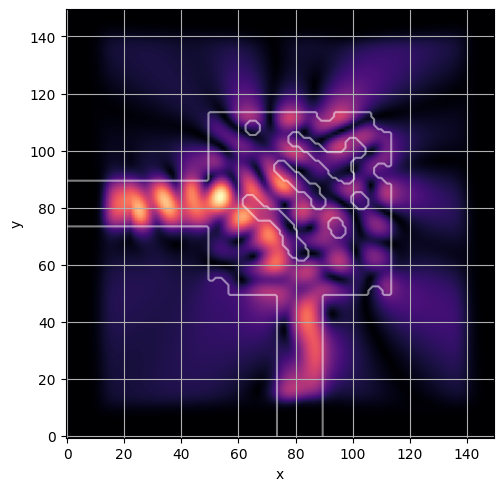
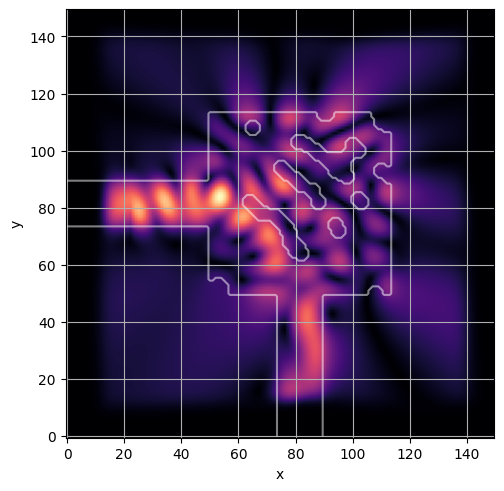
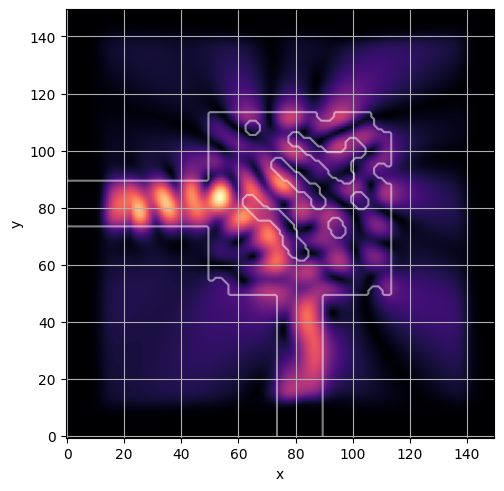
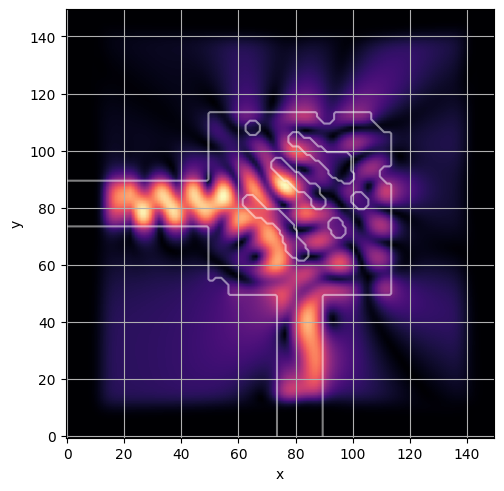
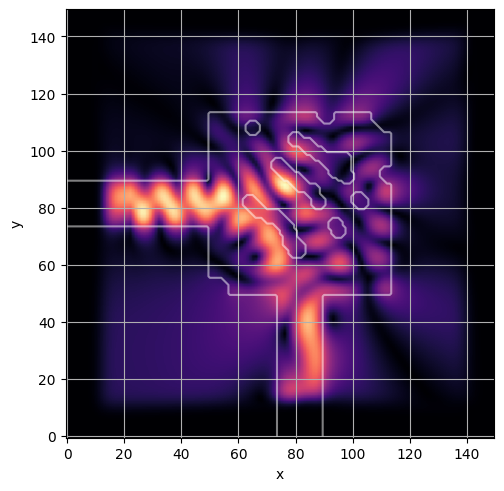
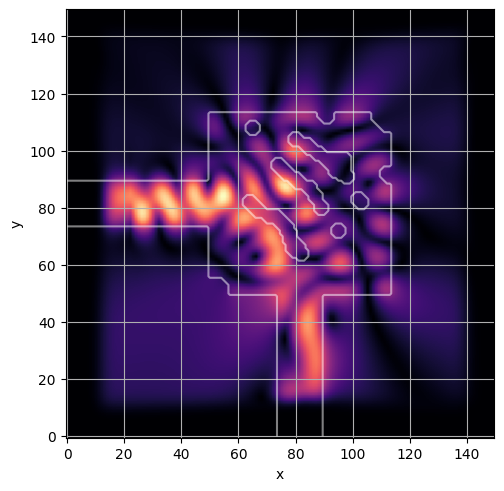
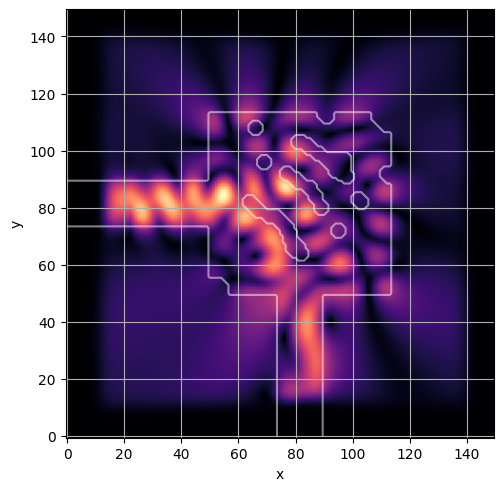
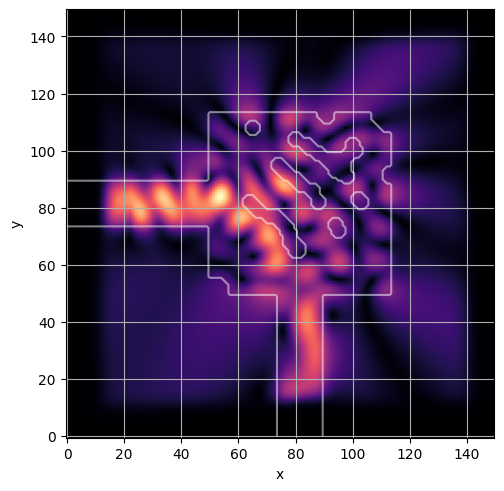
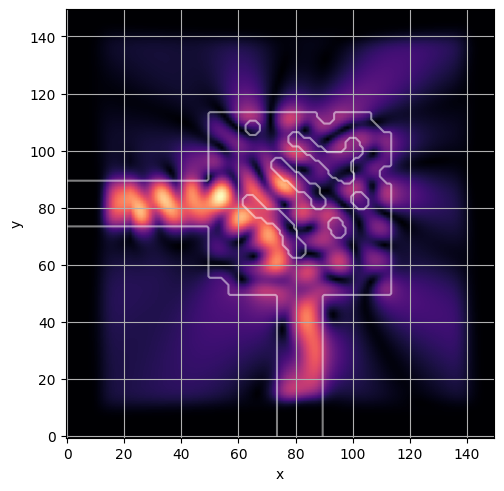
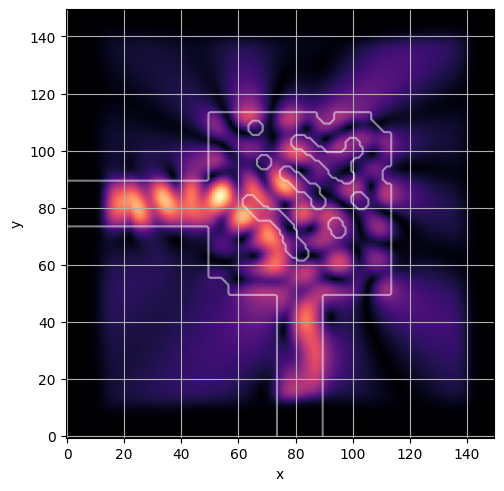
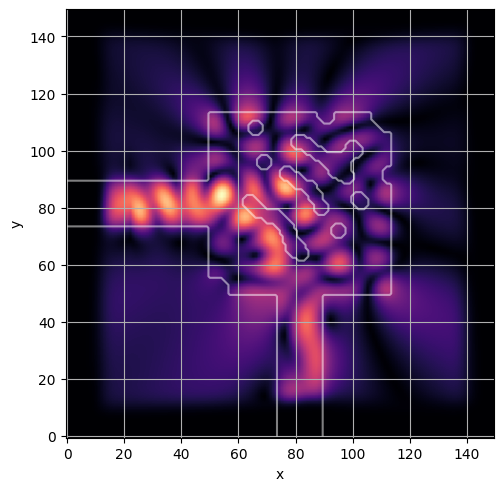
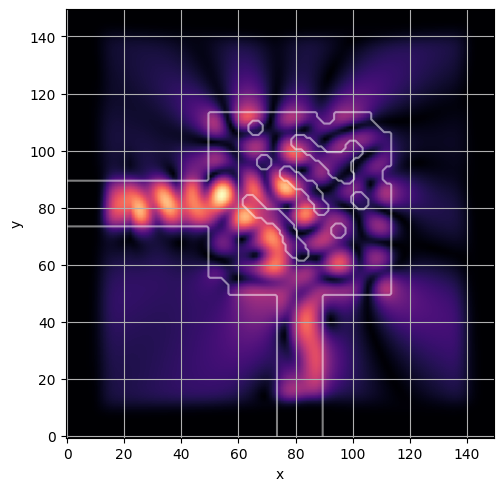
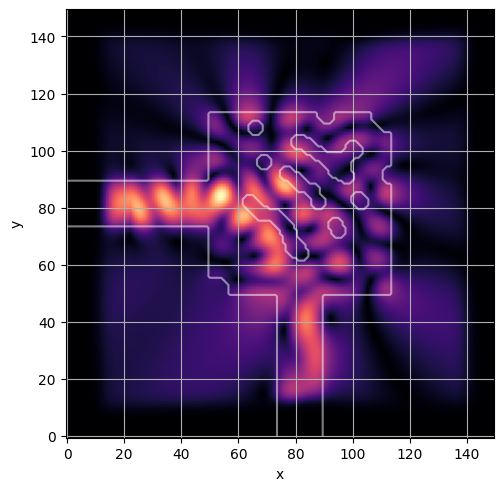
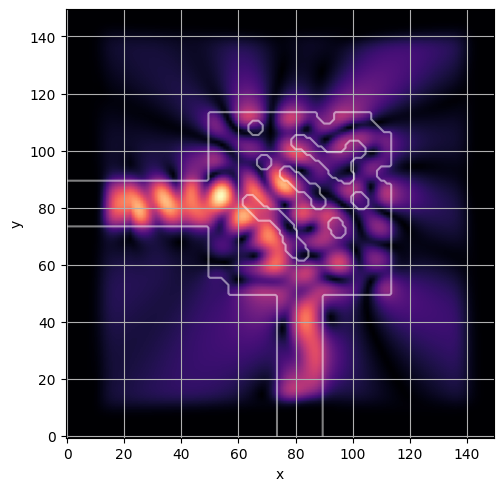
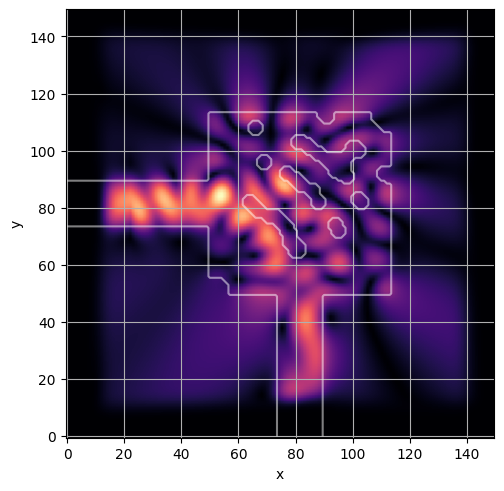
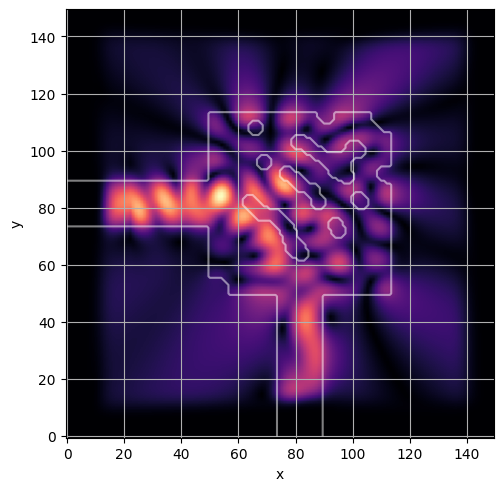
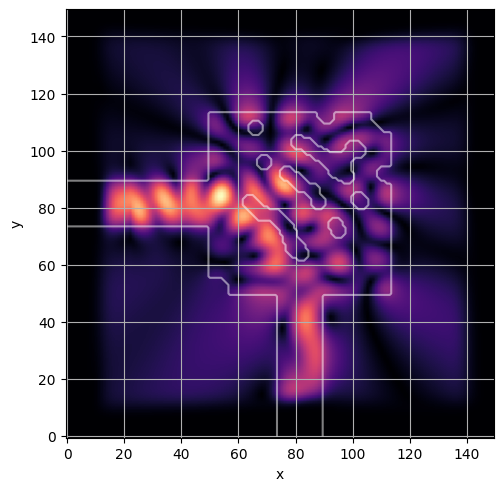
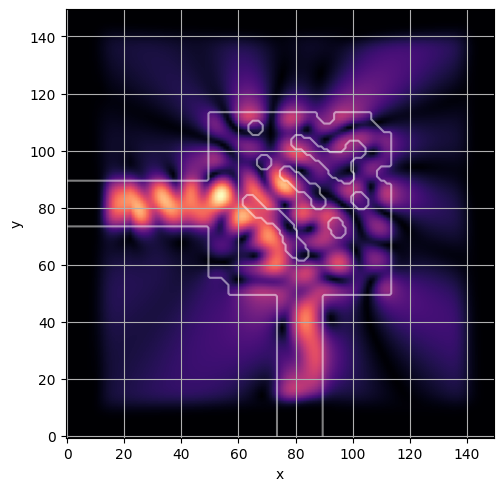
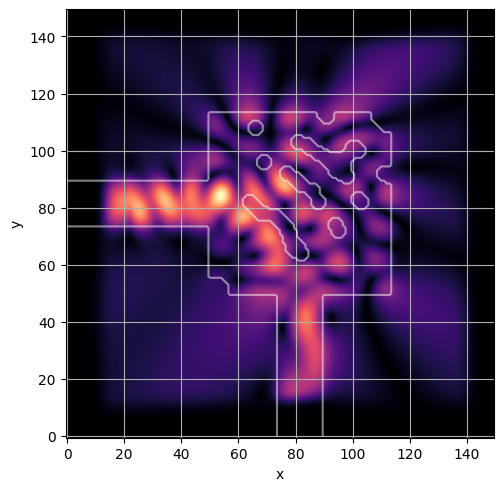
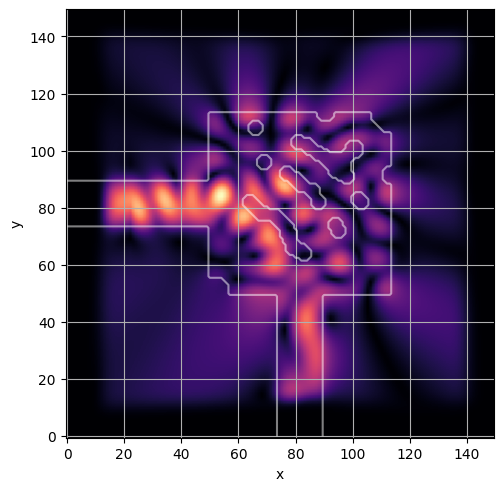
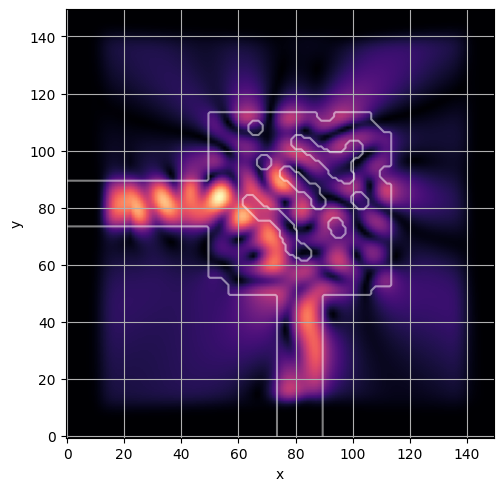
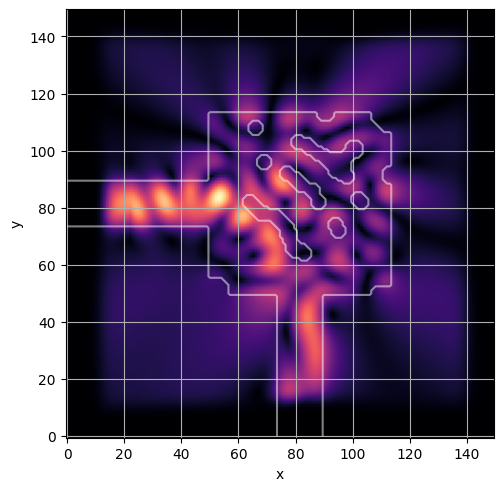
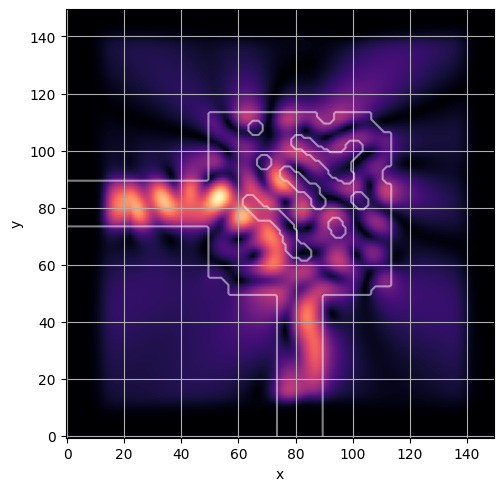
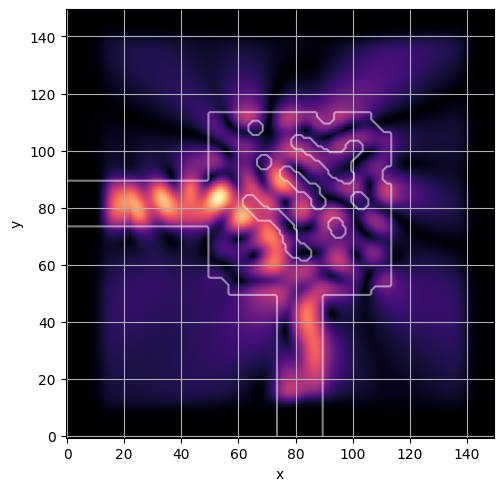
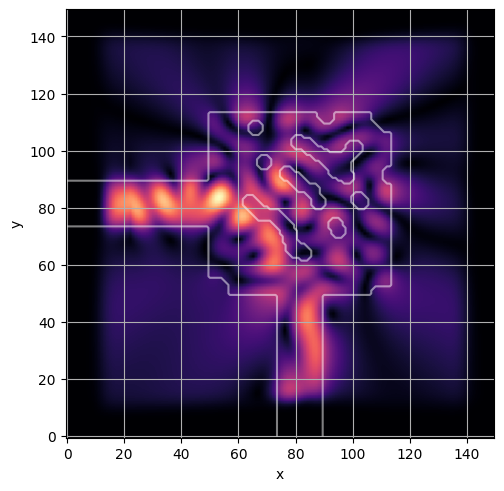
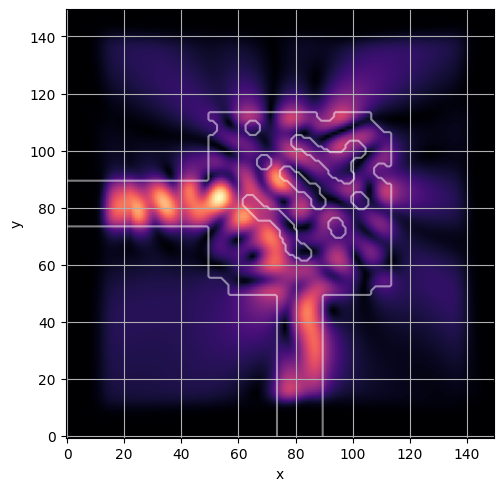
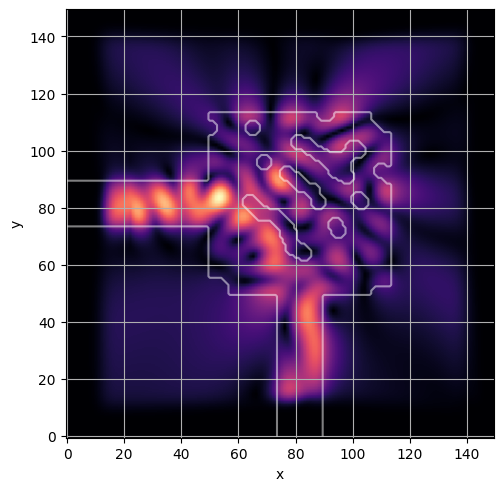
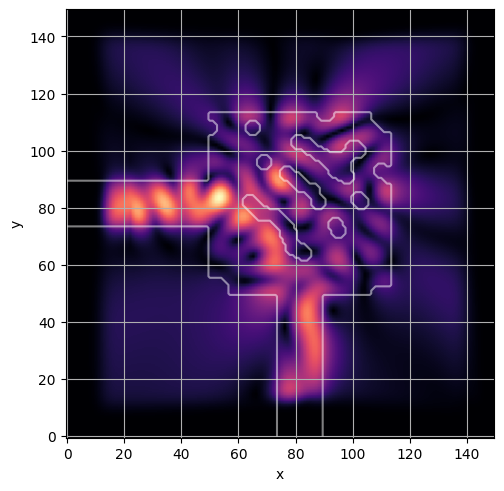
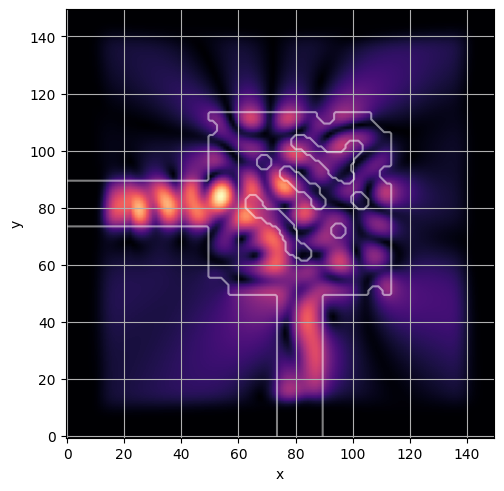
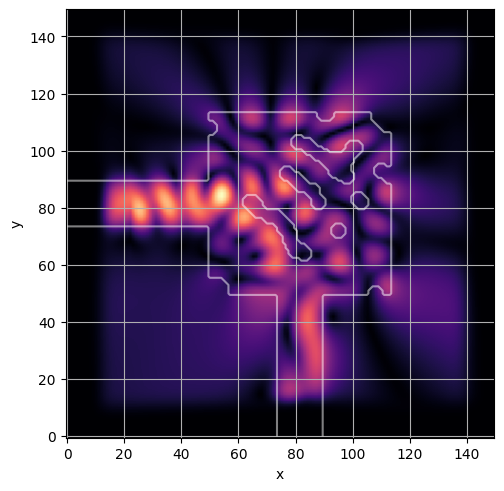
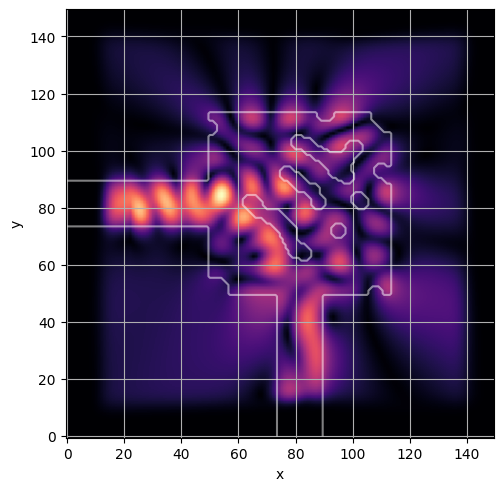
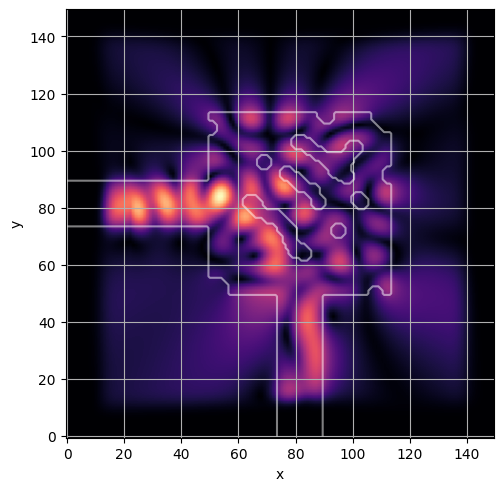
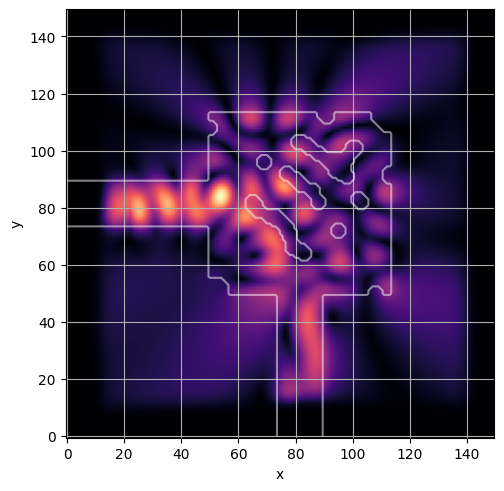
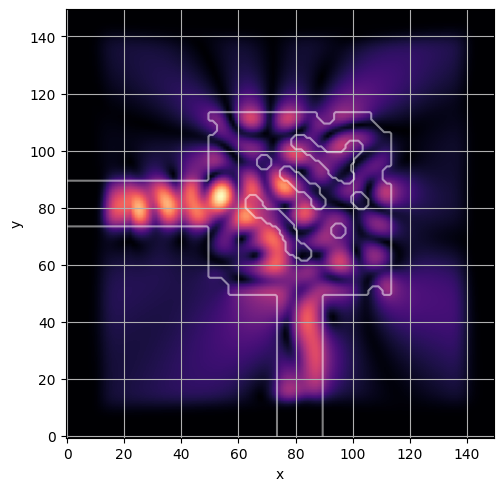
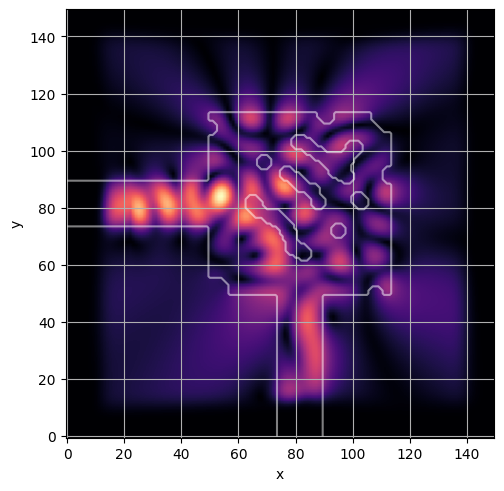
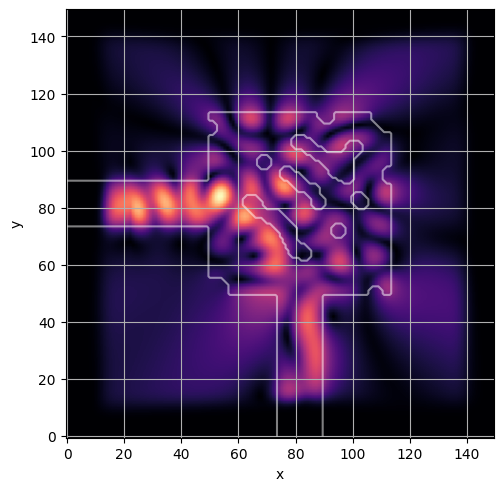
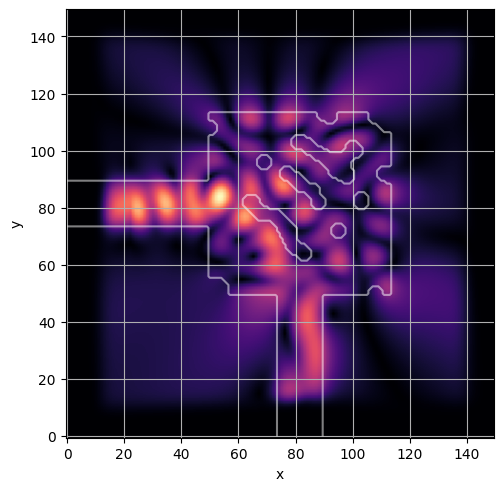
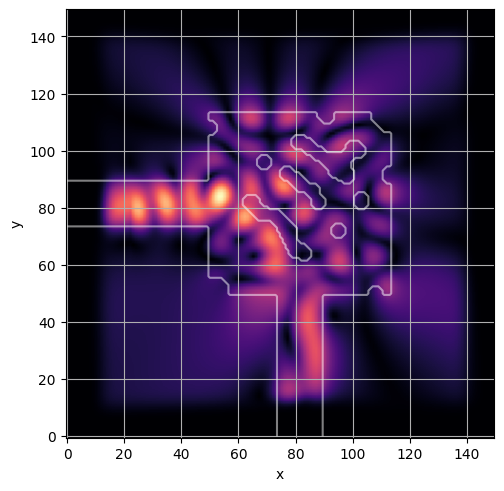
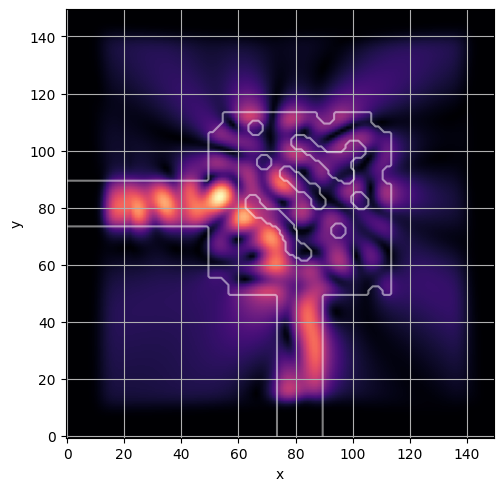
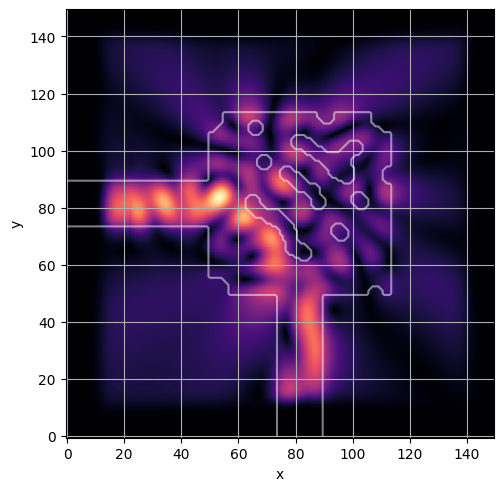
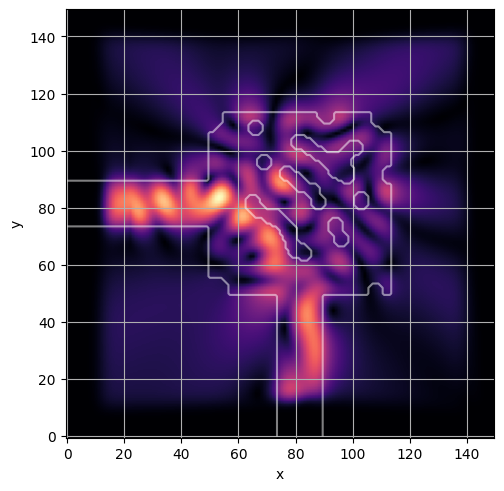
ceviche.viz.abs(np.squeeze(np.asarray(debug_fields)), model.density(np.asarray(debug_design)))
plt.grid()
plt.show()grad_fn = jax.grad(loss_fn)
init_fn, update_fn, params_fn = adam(step_size)
state = init_fn(latent) #.flatten()
#value_and_grad seems to have a problem. Figure out why!
def step_fn(step, state):
latent = params_fn(state) # we need autograd arrays here...
grads = grad_fn(latent)
loss = loss_fn(latent)
#loss = loss_fn(latent)
optim_state = update_fn(step, grads, state)
# optim_latent = params_fn(optim_state)
# optim_latent = optim_latent/optim_latent.std()
visualize_debug()
return loss, optim_statelatent = params_fn(state)
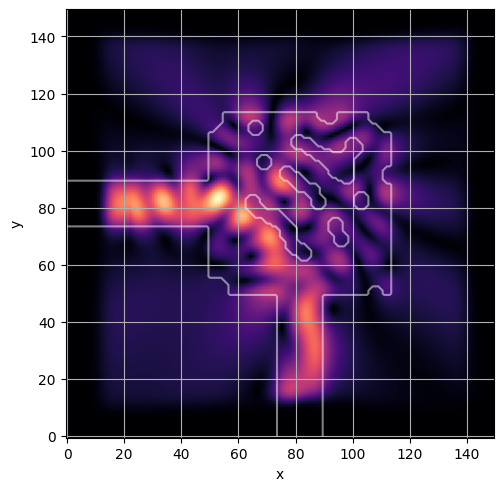
visualize_latent(latent)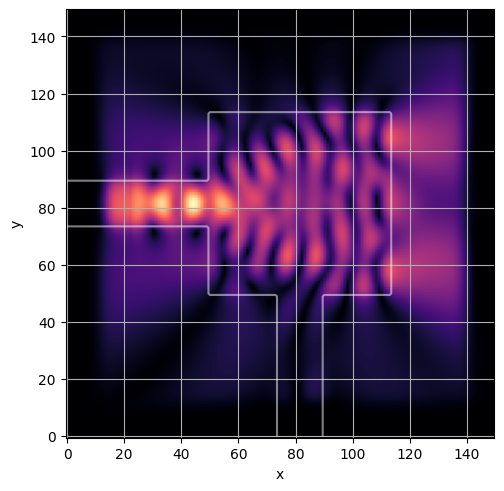
range_ = trange(Nsteps)
losses = np.ndarray(Nsteps)
for step in range_:
loss, state = step_fn(step, state)
losses[step] = loss
range_.set_postfix(loss=float(loss))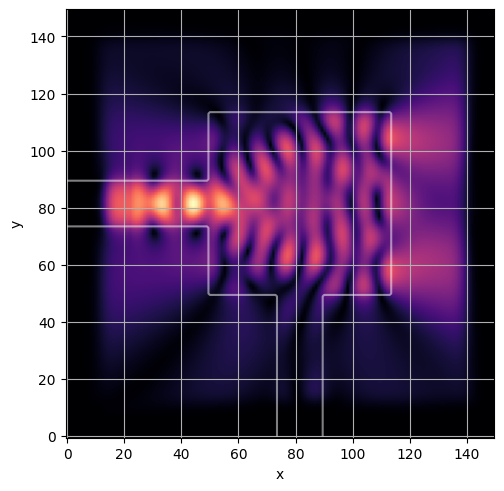
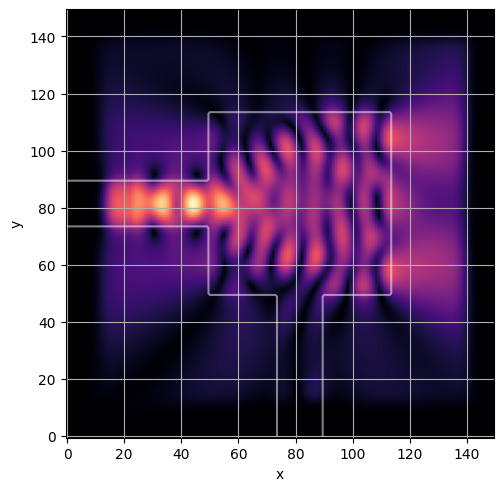
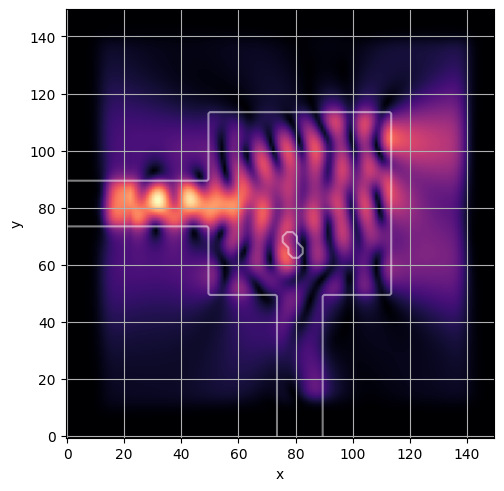
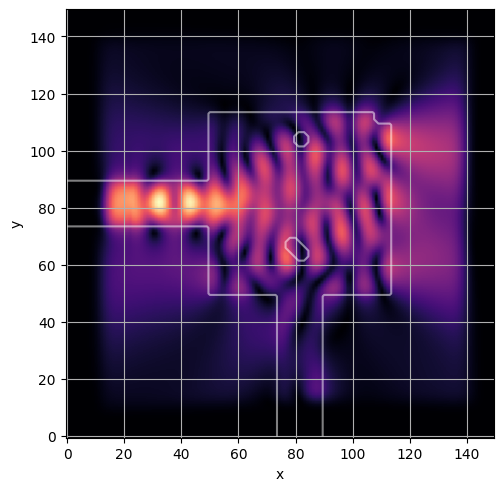
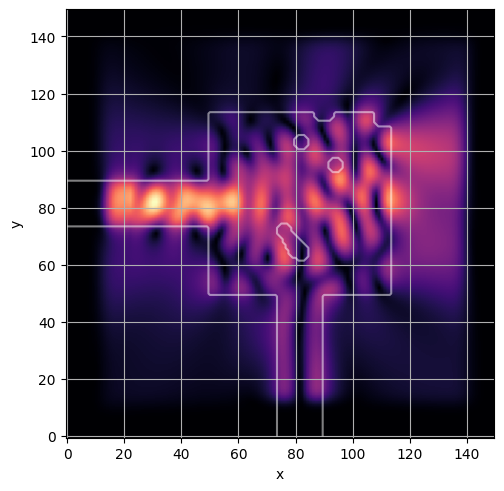
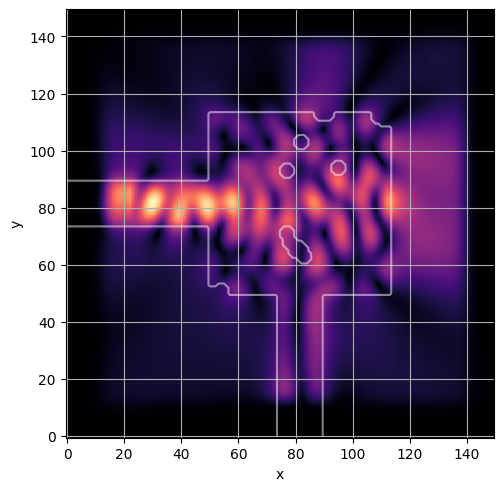
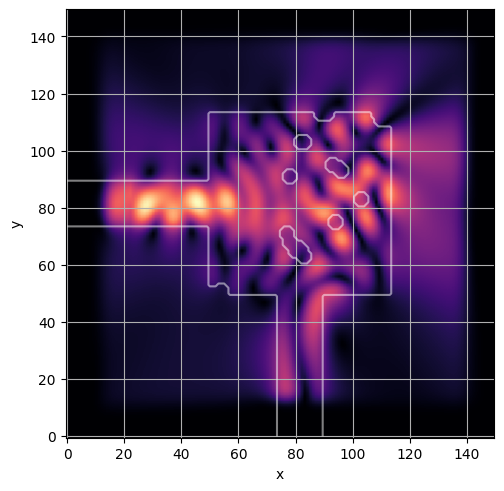
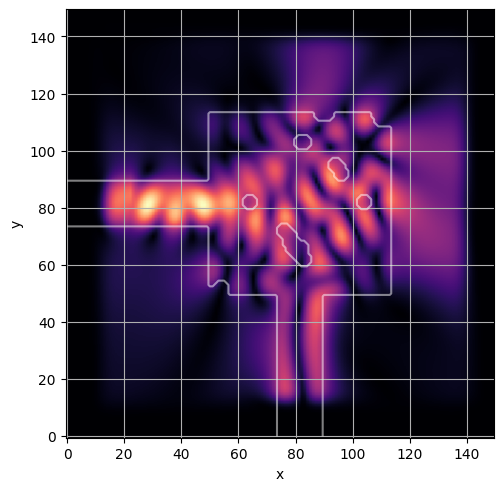
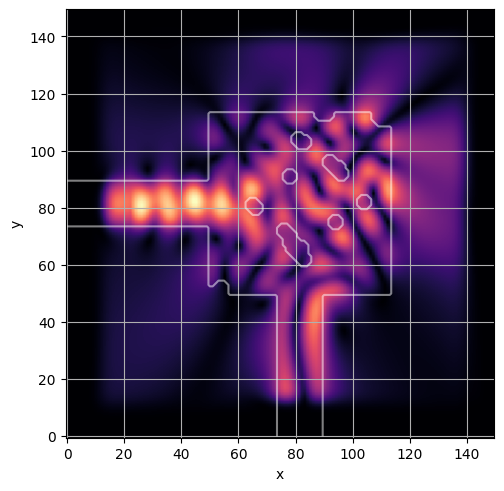
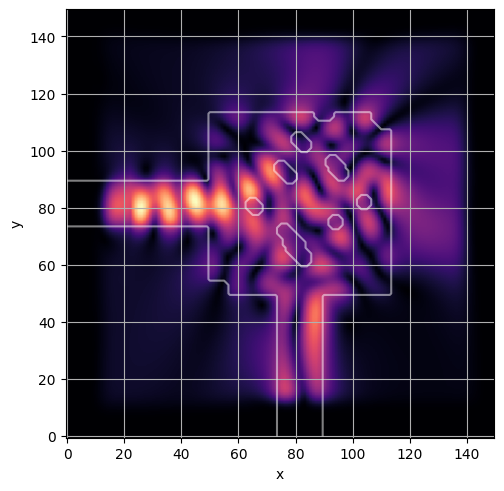
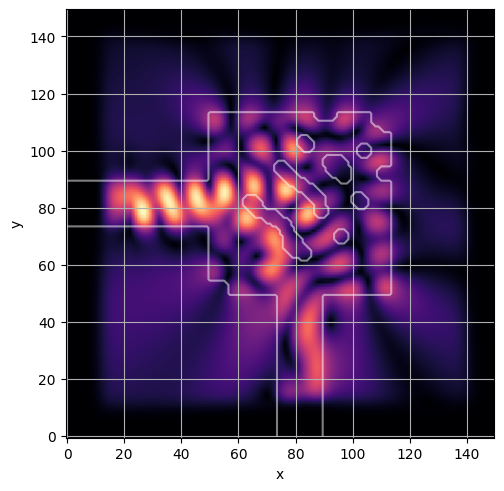
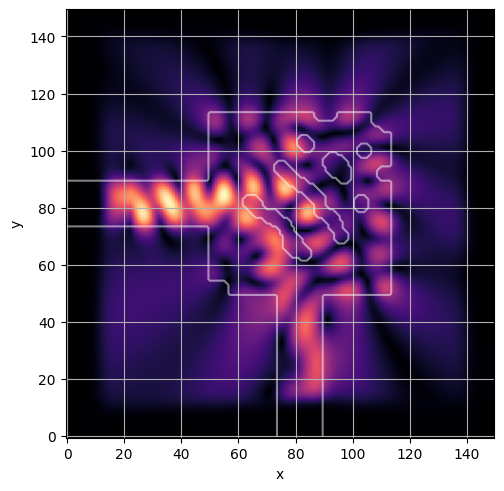
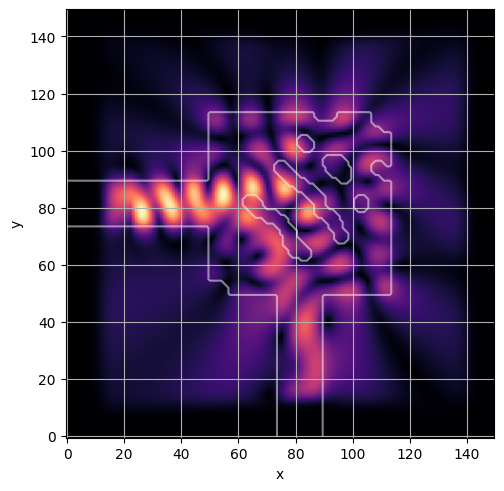
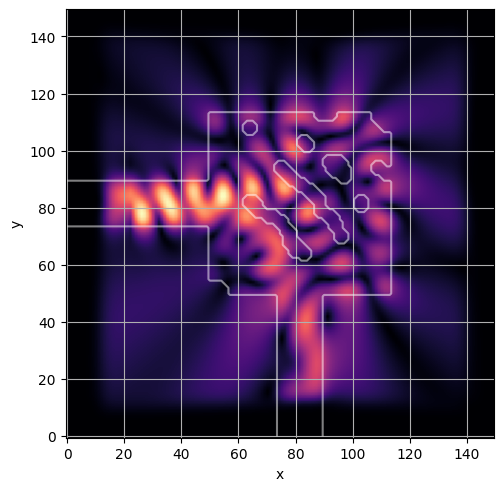
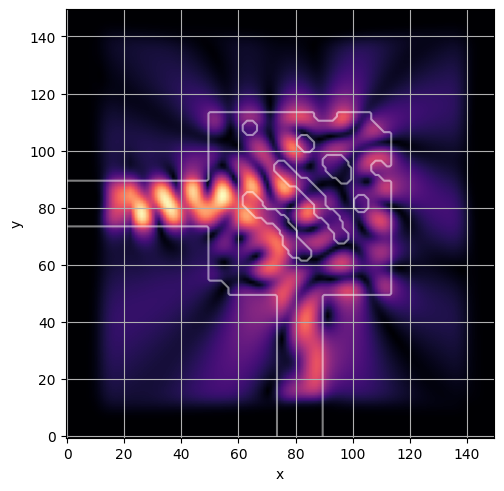
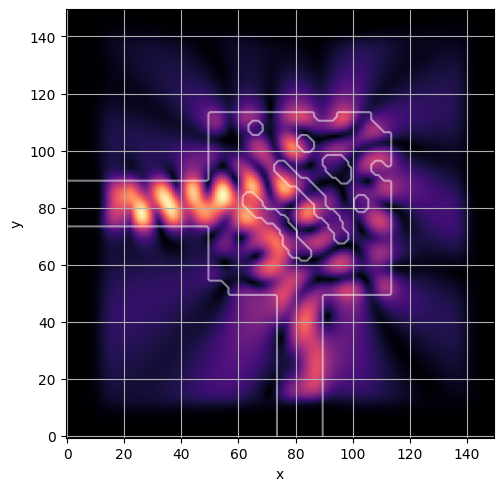
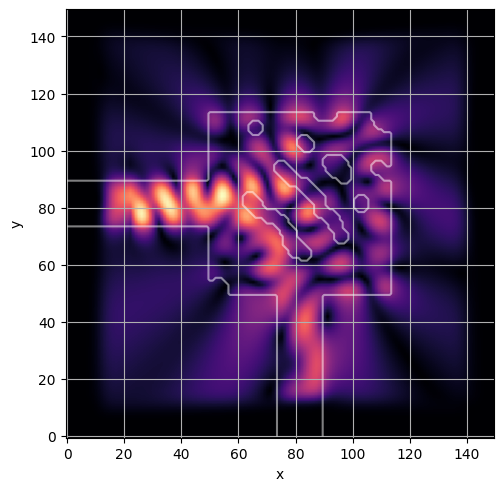
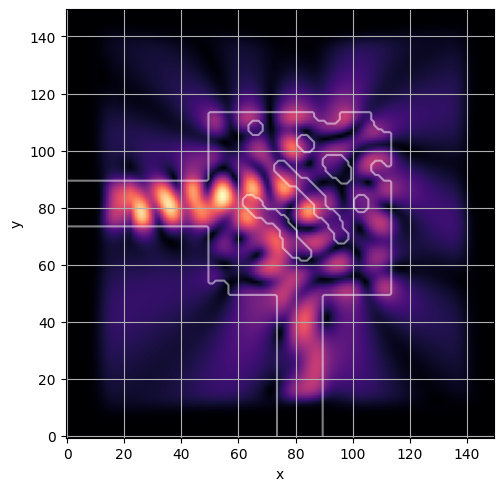
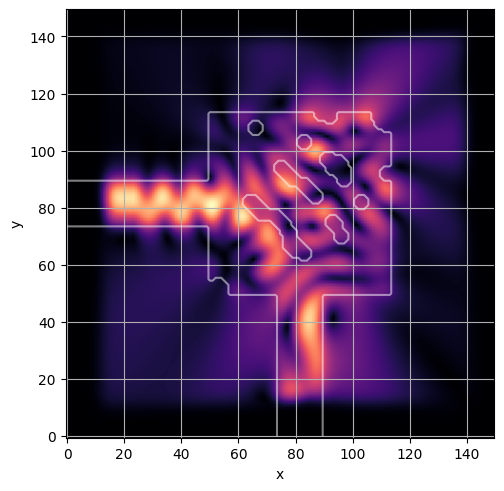
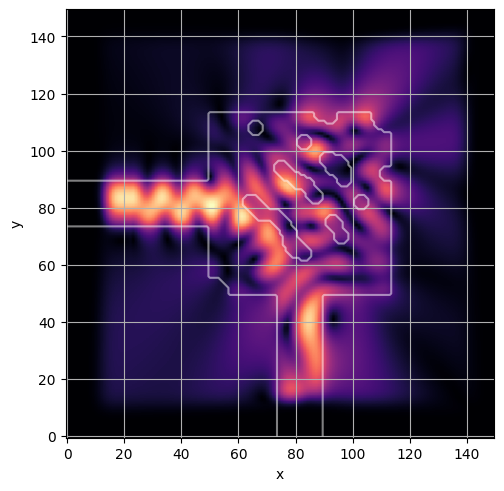
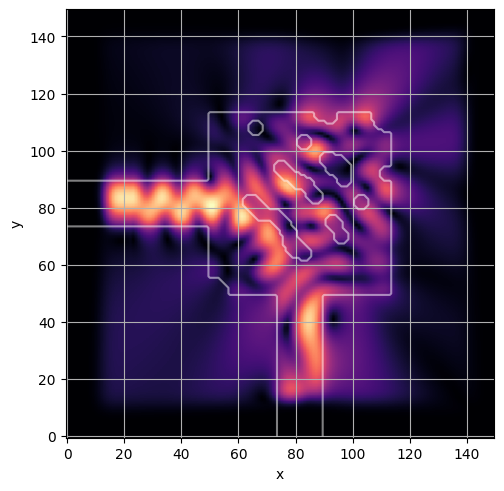
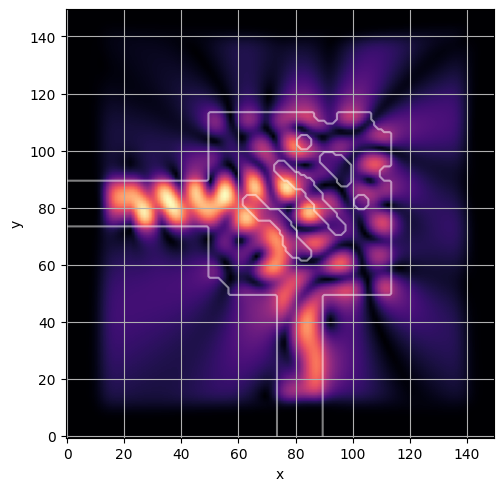
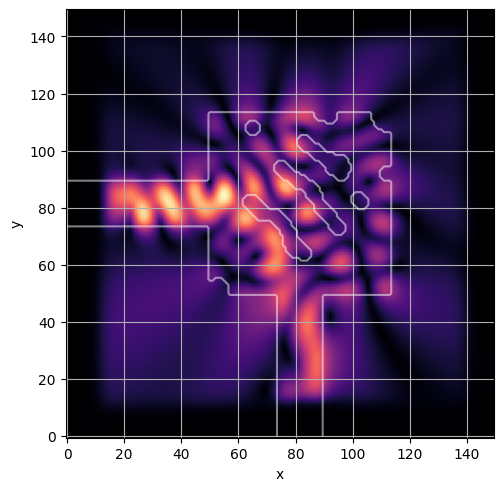
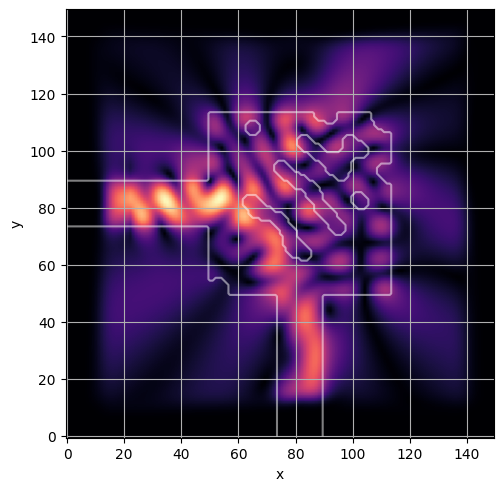
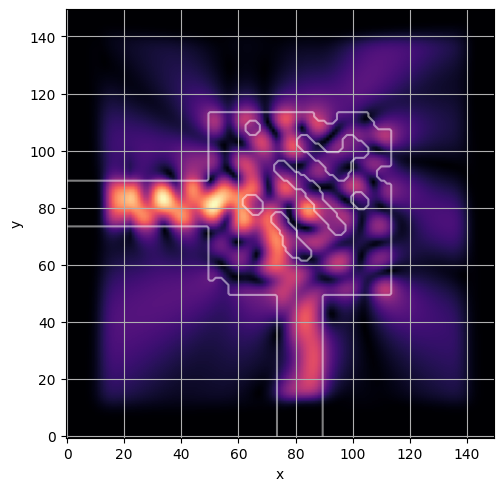
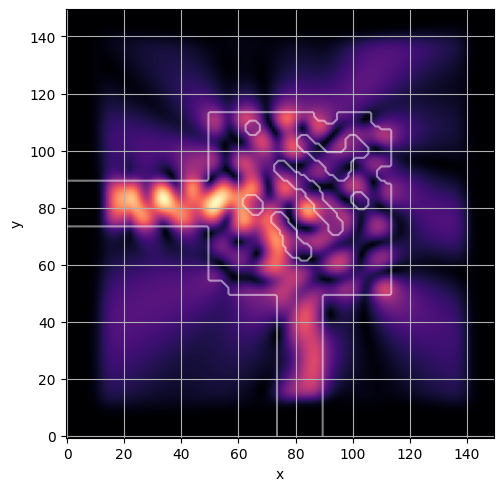
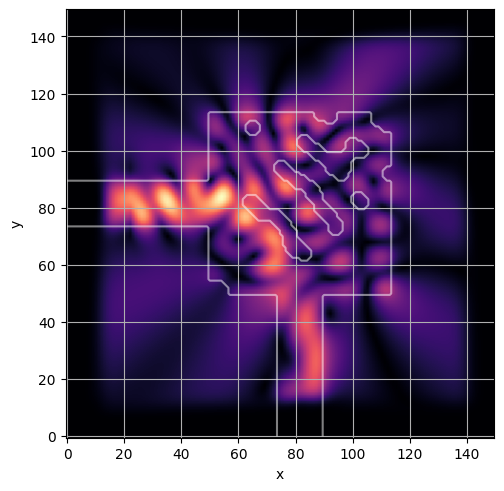
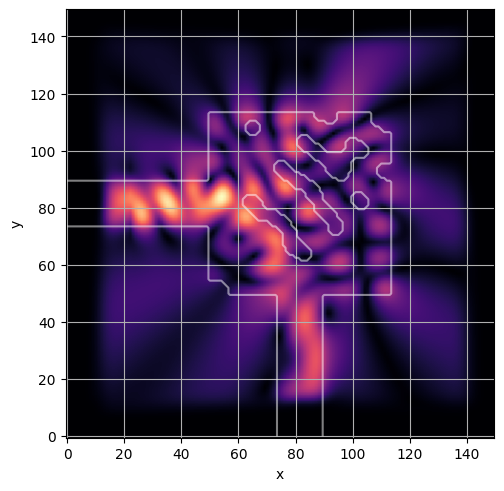
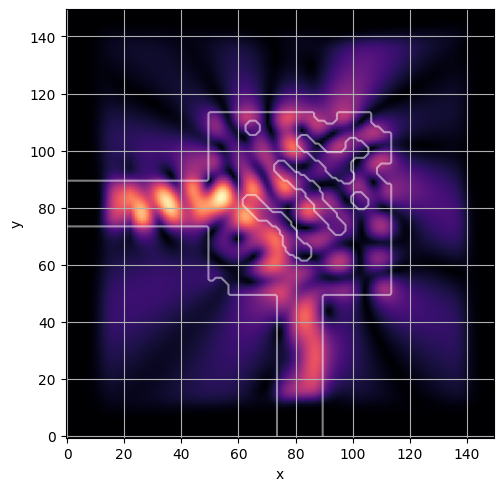
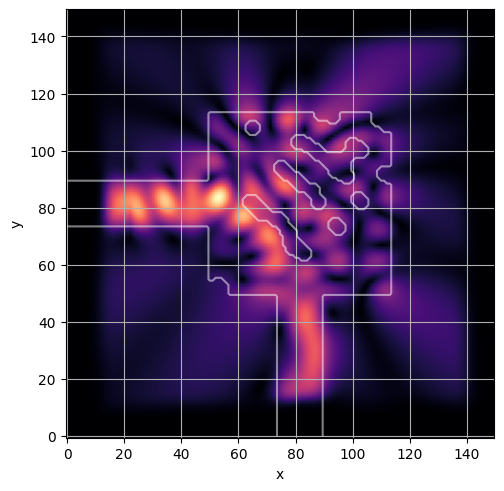
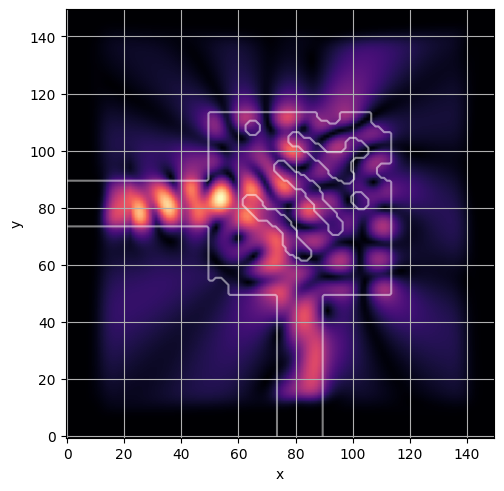
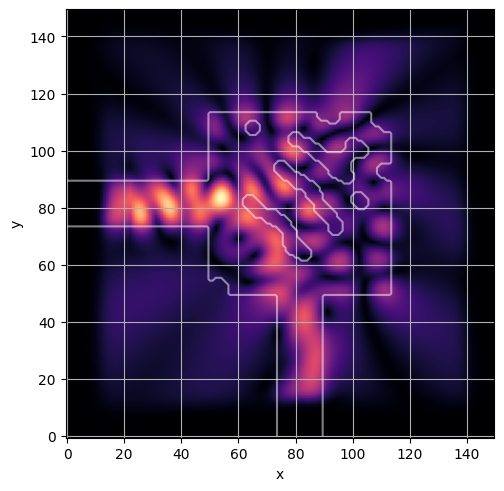
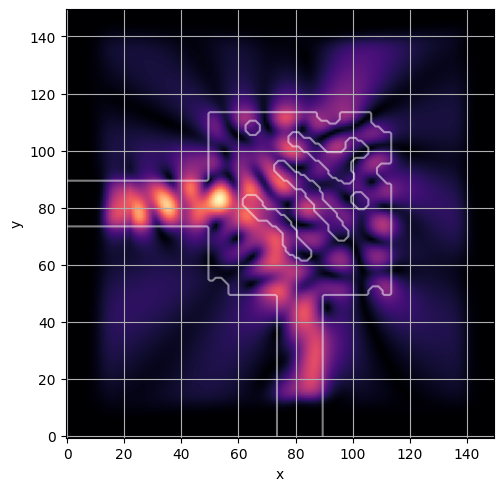
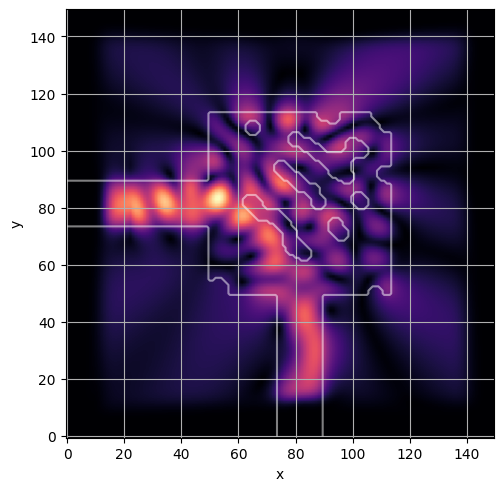
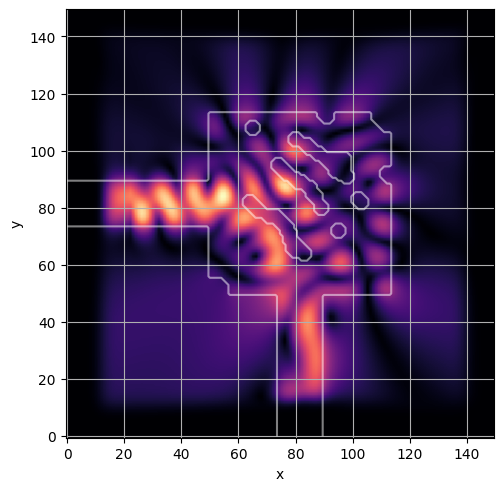
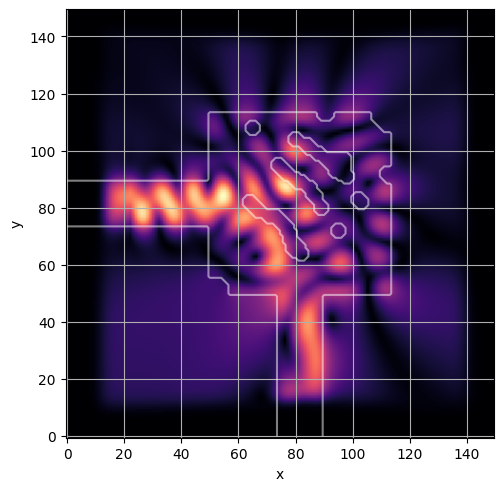
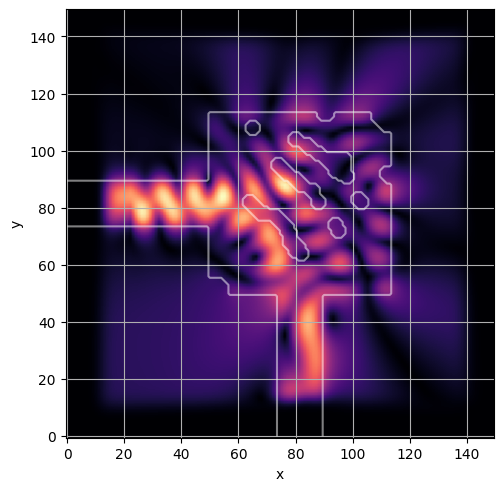
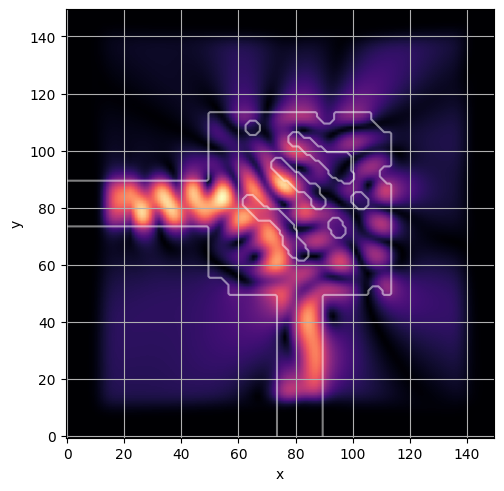

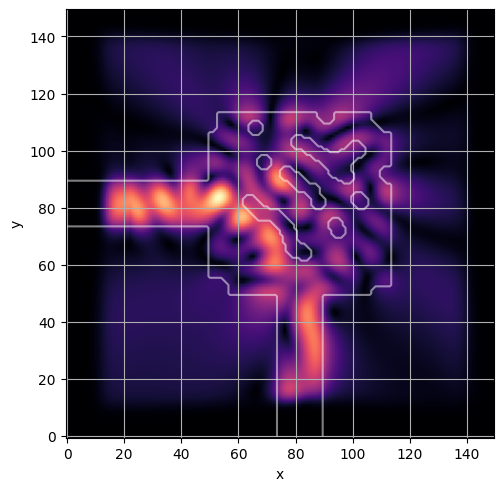
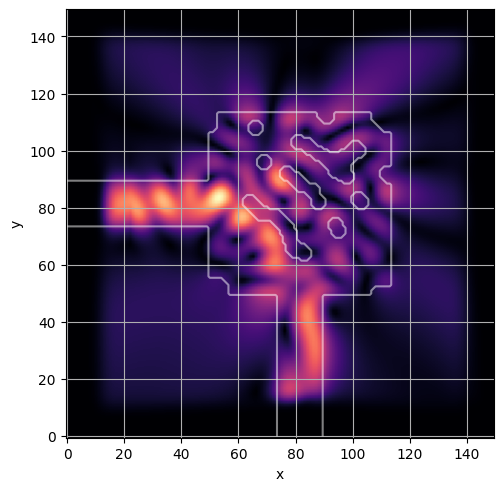
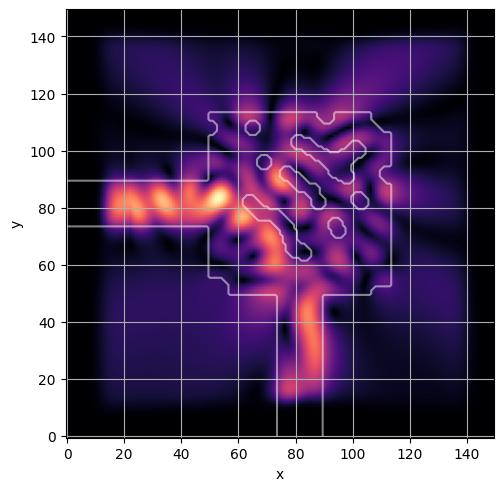
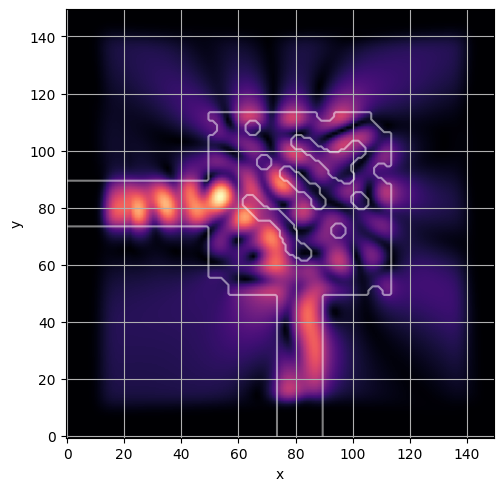
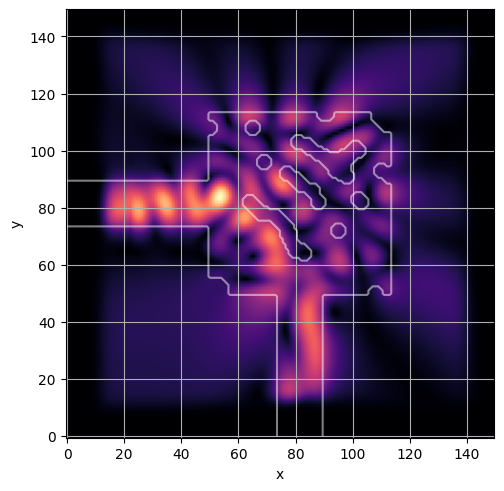
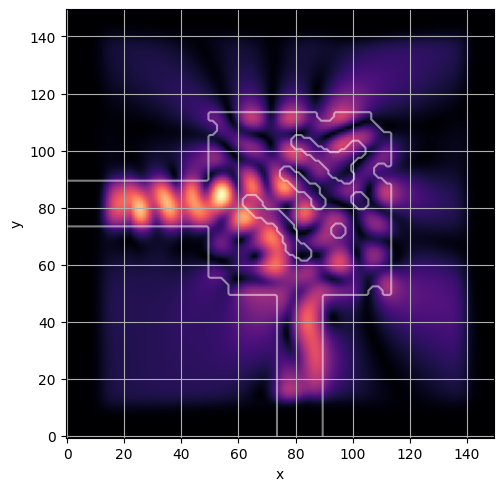
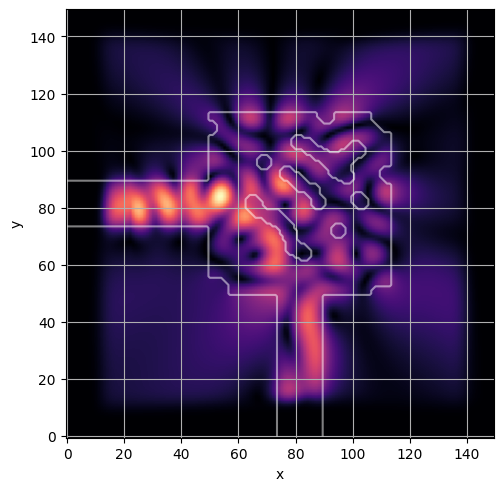
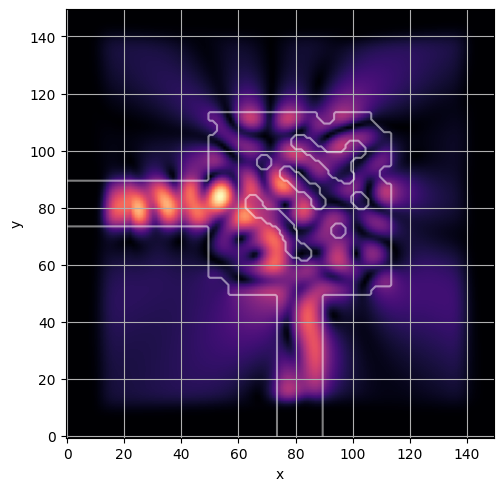
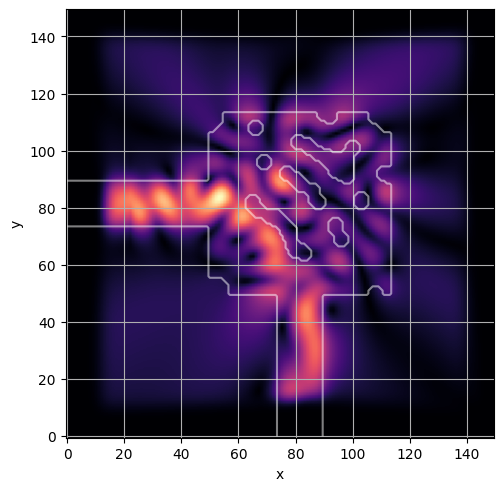
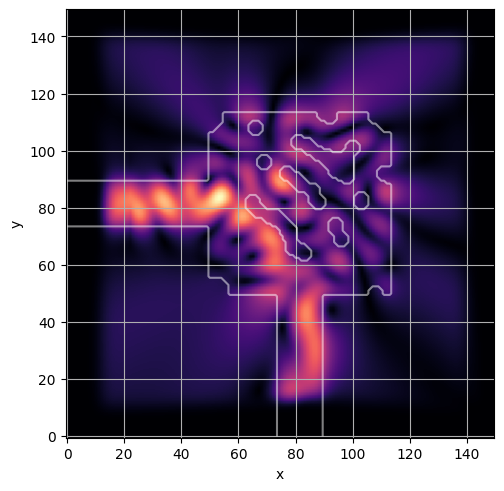
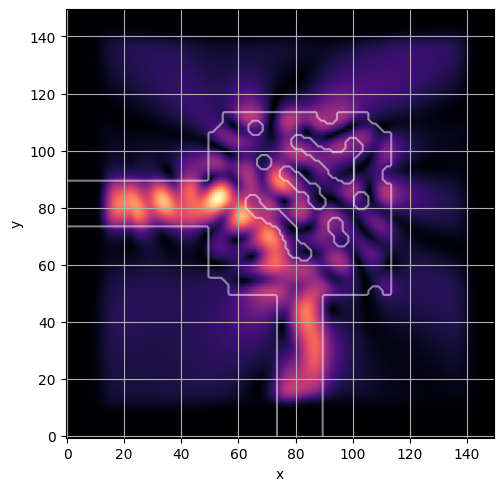
latent = params_fn(state)
design = forward(latent, brush)
s_params, fields = model.simulate(design)
epsr = model.epsilon_r(design)
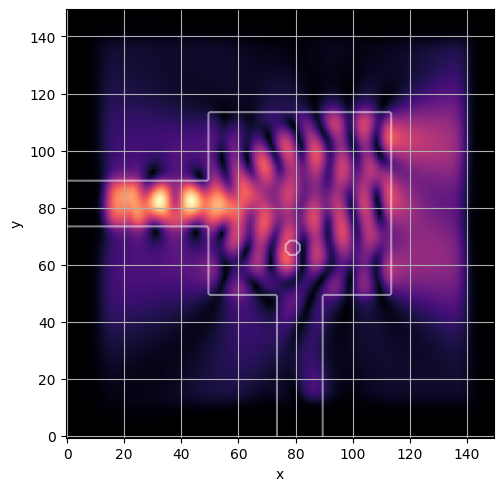
ceviche.viz.abs(np.squeeze(fields), model.density(design))
plt.grid()